A Roadmap for Disclosure Avoidance in the Survey of Income and Program Participation (2024)
Chapter: 6 Disclosure Limitation Approaches: Synthetic Data
6
Disclosure Limitation Approaches: Synthetic Data
OVERVIEW OF DATA SYNTHESIS
Data synthesis is a technique for statistical disclosure limitation, as discussed in Chapter 4. It generates individual-level data (microdata), synthesized based on information in the original dataset. The resulting surrogate data have the same structure as the original data and are, generally, generated using predictive modeling. If the data synthesis model preserves the statistical properties and population-level signals of the original data, then inferential approaches for analyzing synthetic data are appropriate, and the approach enables data users to make valid inferences for a variety of analyses.
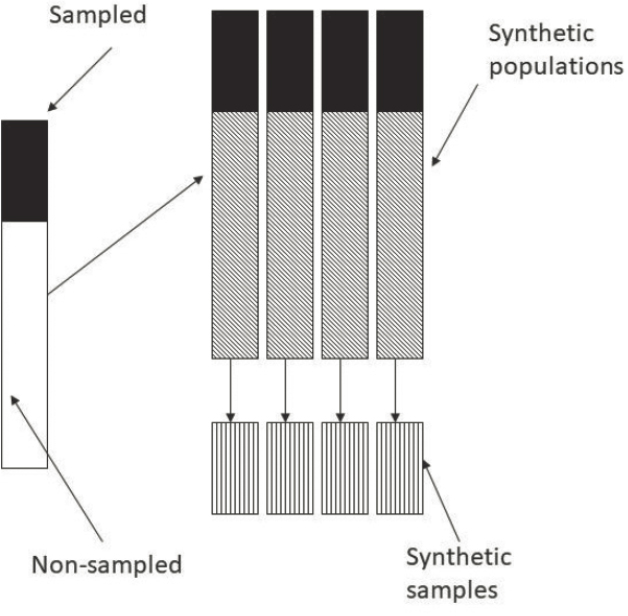
Synthetic data generation as a disclosure limitation approach, which was originally proposed by Rubin (1993), is referred to as the full synthesis approach. The idea of full synthesis uses a standard missing-data paradigm, by which survey outcomes for individuals not sampled in a survey are treated as missing and are multiply imputed using predictive modeling. This generates synthetic populations. Samples from these synthetic populations are then released as public-use files. Given the large population size in the synthetic populations, the original survey values are excluded when drawing these samples. Valid inferences can be constructed when these public-use files are analyzed properly using the combining rules discussed in Raghunathan et al. (2003). It has been argued, however, that in certain cases a single implicate could be sufficient (see Klein & Sinha, 2015; Klein et al., 2019; Raab et al., 2018).
It may not be necessary to fully synthesize a survey dataset to achieve the desired level of disclosure risk. Little (1993) proposed the partial synthesis approach, where only a subset of variables on sampled individuals is synthesized. Assume that the variables in a dataset can be categorized as either quasi-identifiers or sensitive variables.1 The pseudo-identifiers are characteristics of individuals (such as sex, race, and zip code) that are available to data intruders in publicly available sources. Sensitive variables are the responses collected in a study or a survey and may include sensitive information about individuals. Partial synthesis methods may focus on only synthesizing sensitive variables so that intruders would only know the synthetic rather than the actual responses, or synthesizing only quasi-identifiers to prevent record linkage through them, or both. Synthesizing only quasi-identifiers is better in terms of retaining information, especially when response variables outnumber quasi-identifiers significantly, since only a smaller set of variables would be sanitized to protect the information of a much larger set. Reiter (2003) developed combining rules for partially synthetic datasets.
Little et al. (2004) proposed selective synthesizing (partial synthesis), where one synthesizes for only a selected subset of the sample individuals, such as those at high probabilistic disclosure risk or the cases deemed most likely to be identified by data intruders. For example, synthesizing quasi-identifiers for selected individuals may involve probabilistic swapping of quasi-identifiers between paired cases. Synthesizing selected cases in the sample incurs less information loss and reduced sensitivity of inferences to synthesis model misspecification than partially synthesizing all cases, at the expense of weakening the guarantee of privacy protection. As with the full synthesis approach, multiple synthetic sets of identical structure can be released using partial synthesis to propagate the uncertainty arising from the synthesis process.
Figures 6-1 to 6-3 illustrate the three versions of synthetic datasets (taken from Raghunathan, 2016).
- Figure 6-1 illustrates fully synthetic data where all the variables are synthesized on all respondents. This is generally a very difficult task for a large and longitudinal dataset like the Survey of Income and Program Participation (SIPP).
- Figure 6-2 illustrates partially synthetic datasets where a selected set of variables that are deemed sensitive or key to potential identification are synthesized on all respondents in the survey. The list of
___________________
1 The distinction between quasi-identifiers (QIDs) and sensitive attributes has increasingly blurred. Sensitive attributes can be used as QIDs and some QIDs may also contain sensitive values. In other words, QID and sensitive attributes may vary case by case and differ in their context (see Narayanan & Felten, 2014; Sei et al., 2017; Wong et al., 2019).


SOURCE: Raghunathan, 2016.
- variables to be synthesized may be determined, for example, based on a re-identification study, as described in Chapter 3. Suppose S is a set of variables to be synthesized and P is a set of variables that can be included in the public-use file. The partial synthesis can be created based on the prediction modeling, f(S|P).
- Figure 6-3 illustrates a situation where the variables in S are synthesized for a subset of respondents. The approach is the same as in the partially synthetic data—namely, based on a prediction modeling, f(S|P), but only based on the subset. The subset is determined based on the level of individual risk of disclosure. Note that the synthesis of the full sample data (i.e., everyone in the sample is regarded as a sensitive subject) without using any population information is a special case of the scenario depicted in Figure 6-3. This is also referred to as full synthesis in the literature.
In summary, “synthetic datasets, generated to emulate certain key information found in the actual data and provide the ability to draw valid statistical inferences, are an attractive framework to afford widespread access to data for analysis while mitigating privacy and confidentiality concerns” (Raghunathan, 2021).
In addition to the information provided in this chapter, Appendix B provides technical information about inferences based on multiple synthetic data.
DATA SYNTHESIS APPROACHES
Many approaches and techniques have been developed in the past several decades for both partial and full synthesis. The panel loosely groups the data synthesis methods into two categories: distribution-free
or non-parametric approaches and distribution-based or parametric approaches. In the former, a data synthesizer is constructed without making assumptions that the sample data are drawn from a particular probability distribution, and in the latter it is constructed based on an assumed parametric distribution or a statistical model for the sample data.2
A straightforward distribution-free approach is to first estimate the probability distribution of the sample data using a non-parametric method, such as histograms and kernel density estimation. Then samples are generated from the estimated distribution to create synthetic data. Both histograms and kernel density estimation are well studied and have established theoretical results. Despite their simplicity, they are known to be subject to the “curse of dimensionality.”3 Reiter (2005b) examines the feasibility of using CART (Classification and Regression Trees) to generate partially synthetic data.4 Burgette and Reiter (2010) propose using regression trees as the conditional models in the sequential regression approach to impute missing values, which yield more reliable imputed data than standard parametric sequential regression techniques. The technique was later used to generate synthetic data in Bonnéry et al. (2019), Drechsler and Reiter (2011), El Emam et al. (2020), Quintana (2020), and Raab et al. (2018), among others.
Sequential trees as a data synthesis approach have the advantage in that datasets can be heterogeneous in the variable types, even with a significant amount of missing values, without making any assumption about the distribution of each attribute.
An and Little (2007) propose a non-parametric stratified hot-deck procedure through creating strata and drawing removed quasi-identifiers with replacements from each stratum, and they tested the approach in longitudinal studies. Pistner et al. (2018) propose using quantile regression to address the heavy-tailed heteroscedastic nature of the Longitudinal Business Databases (LBD) to create a version of synthetic LBD, and compare their proposal in both utility and privacy with the use of CART. Yu et al. (2022) use non-parametric and semi-parametric regression techniques to generate longitudinal synthetic data.
Modern data generation based on deep learning techniques also belongs to the distribution-free category, as it does not make any assumptions
___________________
2 There are other categorizations along similar lines, such as parametric vs. non-parametric approaches. Note that some data synthesis approaches are distribution-free but are model-based and contain parameters, such as deep generative models.
3 As the number of dimensions increases, the available data become increasingly sparse, making it difficult to obtain meaningful estimates.
4 CART works by recursively partitioning the sample data into smaller subsets given the observed attributes and creating a tree-like model that can be used for prediction or classification of an outcome.
about the underlying probability distribution for the sample data. These deep data generation techniques work with various types of data, such as numerical data, categorical data, and unstructured data (such as graphs, networks, and text).5 The techniques have been shown empirically, in numerous experiments, to be capable of generating synthetic data that resemble the original. On the other hand, they do involve training large deep neural networks with tens of thousands of parameters, and there is still a lack of understanding on why they work.
In contrast to distribution-free synthetic data approaches, distribution-dependent data synthesis starts with the specification of an appropriate statistical model or a probability distribution for the observed data, referred to as the synthesis model, based on which synthetic data will be generated. This method then estimates the parameters in the model or distribution given the data, and finally generates data from the model given the estimated parameters. To account for the uncertainty around the estimated parameters in the synthesis model, a Bayesian approach can be useful and easy to implement as well. In such an approach, first one draws model parameters from their posterior distribution, and then one builds synthetic data from the distribution assumed for the observed data given the drawn posterior samples in the previous step. When a dataset has a large number of variables, including longitudinal data, synthetic data can be generated using sequential regression (Raghunathan et al., 2001). The order in which the sequential regressions are performed can be randomized. The sequential modeling framework has been successfully implemented in practice for missing data imputation and data synthesis—for example, for IVEware (Barrientos et al., 2018; Kinney et al., 2014; Raghunathan et al., 2016)—and is currently the method behind SIPP Synthetic Beta.
Little et al. (2004) provide a couple of approaches for model-based partial synthesis of quasi-identifiers. The first approach is to synthesize the quasi-identifiers in a mixed set of individuals who are at high disclosure risk and who are at low risk, where the latter group is similar to the former in terms of the sensitive attributes based on a similarity measure, such as the Mahalanobis distance. Synthesis models need to be carefully defined, since the selection of the low-risk group is not random. An alternative is a model-based probabilistic swapping of quasi-identifiers between individuals who are at high disclosure risk with individuals who are at low risk, both groups having similar or matched values on sensitive attributes.
Distribution-dependent approaches may not be as robust as distribution-free approaches, in the sense that synthetic samples would be biased if
___________________
5 For example, variational autoencoders (VAEs; Kingma & Welling, 2013, updated in 2022), generative adversarial networks (GANs; Goodfellow et al., 2014), normalizing flows (NFs; Papamakarios et al., 2021; Rezende & Mohamed, 2015), and diffusion models (Ho et al., 2020; Song & Ermon, 2019).
distributional assumptions imposed on the observed data are inappropriate. Regardless of whether a synthesis model makes distributional assumption about the sample data or not, to enable analysts to perform unbiased analyses on synthetic data, the synthesis model needs to be “expansive” and must include, as submodels, all models that may be run by analysts on the synthetic data. In the literature on missing data, it is well known that if the imputer model is “uncongenial” (Meng, 1994)—for example, the model to create multiple imputations is a submodel of the one used by an analyst, which is the true model—then inferences based on the imputed data in the analyst model would be invalid. On the other hand, if the imputer’s model is more general and includes the analyst model as a special case, then the inferences based on imputed data, though consistent, may not be as precise if the information from the imputer’s model is not shared with the analyst or incorporated in the analyst’s model.
Disclosure Risk
Work has demonstrated that synthetic data, even fully synthetic data, may still be subject to privacy attacks and are not immune to privacy leaks, although the risks may be different case by case. Privacy attacks on synthetic data can be membership attacks that determine whether a particular individual (target) is in the original sample used to generate the synthetic data. Other privacy attacks on synthetic data include re-identification attacks; attribute inference attacks, where an attacker attempts to learn information on sensitive attributes of individuals; and reconstruction attacks, where an attacker tries to reconstruct the original data from the synthetic data. With advancements in machine learning and the availability of vast amounts of public data, many of the attack tasks can be performed using only the released synthetic data and without knowing the details of the synthesis model; such attacks are known as black box attacks.
Reiter and Mitra (2009) show that the partially synthetic data with quasi-identifiers being replaced by synthetic values are still subject to reidentification attack. Zhang et al. (2022) formulate a membership attack by learning useful representations of observed data without specific assumptions about the generative model. They perform such attacks against synthetic health datasets and find that the records in synthetic data that have a one-to-one correspondence with real records in the population are vulnerable to membership inference at a very high rate. By contrast, synthetic records that are random samples from a distribution and generative model without direct mapping to real records are only marginally susceptible to attack and, in most cases, could be deemed sufficiently protected from membership inference. El Emam et al. (2020) argue that if a model synthesizer is overfitted to the original data, a synthetic record, even in fully synthetic data, can be mapped to a real person in the population, who is
thereby subject to disclosure risk. Deep generative models have also been demonstrated to pose serious privacy risks, because they inadvertently memorize some of their training data (Carlini et al., 2021, 2023; van den Burg & Williams, 2021).
To make synthetic data safer and more robust against privacy attacks, it is important to carefully design data synthesis algorithms and carefully incorporate privacy concepts, such as differential privacy, into the data-generation process.6 Blum et al. (2013) show that in theory there exists a differentially private algorithm that takes a dataset and outputs a synthetic dataset that preserves an exponential number of statistical properties of the original data. However, there is a computational bottleneck to implement such methods in full generality (Ullman & Vadhan, 2020). If one is willing to make some assumptions regarding the distribution of the data or to give up some accuracy on some statistics, differentially private synthetic data of good utility can still be generated, even for data with more complex structures (e.g., see Nixon et al., 2022; Snoke & Slavković, 2018).
Indeed, many techniques and methods have been developed for releasing differentially private individual-level data in the past decade. In the multiple synthesis framework without formal privacy guarantees, the more sets of synthetic data are released, the higher the disclosure risk becomes by aggregating information across the multiple sets. However, when undertaking data synthesis with differential privacy guarantees, the privacy loss of each release can be prespecified and the overall privacy loss over multiple releases can be bounded and controlled using composition theorems for differential privacy. Like the distribution-dependent synthesis approaches without differential privacy, the methods with differential privacy guarantees can also be roughly grouped into distribution-free approaches and distribution-dependent approaches.
When the original data are numerical, a straightforward approach for differentially private data synthesis is to sample from privacy-preserving histograms constructed from the original data, such as by using a perturbed histogram or smoothed histogram approach (Wasserman & Zhou, 2010).7 To generate privacy-preserving histograms, one can perturb the bin counts in the original histograms using a differential privacy mechanism, and
___________________
6 It should be noted that incorporation of differential privacy in data release does not imply that privacy risk is reduced to zero even if privacy loss approaches zero. See an example in Liu and Zhao (2023).
7 Wasserman and Zhou (2010) also propose generating data from differentially private empirical cumulative density functions. This approach does not seem to be a viable choice in practice (Bowen & Liu, 2020). One difficulty lies in defining the set of all possible candidate cumulative density functions, the size of which increases rapidly with sample size or number of attributes, making the synthesis process computationally challenging and unrealistic for a large or high-dimensional dataset.
then synthesize numerical data by drawing a bin according to the relative perturbed frequencies of the histogram bins and then sampling data from the uniform distributions bounded by the sampled bin endpoints in the previous step. Histogram-based approaches have several limitations. First, to form histograms on the numerical data, discretization is necessary (Scott, 2015). In addition, these approaches suffer from a curse of dimensionality. Specifically, there can be a huge number of data bins/cubes if high-order interactions exist among the data attributes and are taken into account when the histogram is generated; this results in many bins with small or zero counts, which become obscured when noise is introduced. Hall et al. (2012) propose perturbing kernel density estimators with properly calibrated noise to yield differential privacy guarantees, from which synthetic data can be generated. Like histograms, kernel-based density estimators also suffer from the curse of dimensionality, a problem that is only exacerbated after factoring in differential privacy.
When the original sample is categorical, synthetic data can be generated through differentially private, low-dimensional contingency tables. While one could construct a full-dimensional contingency table across all the variables in the original data, it is highly unlikely that high-order interactions among attributes would be meaningful either practically or statistically; in addition, a high-dimensional table would also have sparse or small cell counts. To determine the set of the low-dimensional contingency tables, one can choose an order (e.g., two-way or three-way) based on prior or domain knowledge or apply model selection procedures. After the set of tables is selected, one can apply various randomized mechanisms to sanitize the tables with differential privacy guarantees, from which synthetic data can then be generated (Abowd et al., 2022; Barak et al., 2007; Bowen et al., 2021; Eugenio & Liu, 2021; Hardt et al., 2012; Hay et al., 2009; Nixon et al., 2022; Qardaji et al., 2014). There are several key considerations in this process, such as allocation of privacy budgets across the sanitization of different tables and ensuring count consistency across the tables (either through post processing or through constraint optimization, both of which are employed in the TopDown Algorithm by the Census Bureau to achieve disclosure avoidance in the 2020 decennial census; Abowd et al., 2022).
Procedures for differentially private deep generative models have also been developed, such as differentially private GANs (Xie et al., 2018; Xu et al., 2018), GANs and Private Aggregation of Teacher Ensembles combined to generate privacy-preserving synthetic data with differential privacy guarantees (Jordon et al., 2019), differentially private VAEs (Takahashi et al., 2020), and differentially private NFs (Lee et al., 2022; Su et al., 2023; Waites & Cummings, 2021). Due to the iterative nature of these algorithms, privacy loss is tracked over iterations and can use the accounting methods developed for differentially private deep learning
(Abadi et al., 2016; Bu et al., 2020). Some of these methods have been applied to real data with some success. The downside of the deep generative models is that they often require a large amount of data to generate synthetic data of good utility for a given practically reasonable privacy budget, and the quality of the synthetic data can be sensitive to the specifications of algorithmic parameters used during iteration.
Distribution-dependent differentially private synthesis approaches are based on an assumed distribution or an appropriately defined probabilistic model given the original data (Bowen & Liu, 2020). For categorical data, a well-known model-based approach for differentially private data synthesis is PrivBayes (Zhang et al., 2017), which uses a low-dimensional distribution to approximate the full distribution of all variables in the original data by exploring the conditional independence among them rooted in Bayesian networks. The low-dimensional distribution is then perturbed to obtain a differentially private distribution from which synthetic data can be generated. There are also distribution-dependent differentially private data synthesis approaches in the Bayesian framework, such as the Multinomial-Dirichlet synthesizer for categorical data (Abowd & Vilhuber, 2008), sanitization of sufficient statistics in an appropriate Bayesian model for a given sample dataset (Liu, 2022; Park et al., 2020), and differentially privately tempering of the posterior distribution (Foulds et al., 2016; Wang et al., 2015). Synthetic data can be generated by first drawing parameters from the differentially private posterior distribution and then samples from the assumed distribution for the original data, given the drawn parameters. Alternatives to sanitizing a posterior distribution include approaches that incorporate differential privacy in a posterior sampling algorithm that leverage inherent randomness to achieve privacy guarantees (e.g., Markov chain Monte Carlo; see Balle & Wang, 2018; Heikkilä et al., 2019; Li et al., 2019; Yıldırım & Ermis, 2019) and in the analytical approximations of a posterior distribution (i.e., differentially private variational distribution; see Jälkö et al., 2016, 2022; Park et al., 2020; Sharma et al., 2019; Su et al., 2023).
Differential privacy can also be incorporated in sequential regression modeling. To achieve differential privacy guarantees, each regression model used during the synthesis process, which can be a parametric model, a nonparametric model, or a deep generative model, needs to be made private. Despite the flexibility, there are a few potential drawbacks for sequential regression models in the differential privacy setting for generating synthetic data. First, the total privacy budget is divided across all the models employed in the procedure. Within each model, the budget may be further divided, depending on the type of model. Therefore, if there is a large number of attributes, this approach could perform poorly in yielding useful generated synthetic data. Second, many existing regression procedures with differential privacy guarantees only generate privacy-preserving point
estimates for the regression parameters or point-predicted values for the outcome without uncertainty quantification. For valid inference based on differentially private data, each privacy-preserving regression will output not just the parameter estimates but also information about the variability about the estimates.
As is the case for the multiple synthesis framework without differential privacy, selection of an appropriate synthesis model is critical; model misspecification would generate biased samples. If prior knowledge exists to help in selecting a suitable model, then no privacy budget would be spent on picking a model. If the model selection procedure uses the original data from which synthetic data will be generated, then the data curator will have to allocate a certain portion of the total privacy budget to the model selection procedure.
Very recently, motivated by SIPP, researchers have started to investigate the specific problem of generating differentially private longitudinal data in a way that preserves temporal statistics, such as counts over fixed time windows and cumulative trends over time (Bun et al., 2023). However, this initial work only considers low-dimensional data, where each individual has a small number of binary attributes in each time unit.
Statistical Validity
Multiple synthetic sets of identical structure are often released as a way to propagate the uncertainty arising from the synthesis process. Methods have been developed to combine the results from multiple synthetic datasets to yield valid statistical inferences. For multiple synthetic datasets via the population synthesis, Raghunathan et al. (2003) propose a mathematical formula to combine the estimated variance of the estimated parameter of interest within each synthetic dataset (within-set variance) and the variance of the estimated parameter across the multiple synthetic set (between-set variance) to yield a total variance estimate, based on which statistical inference of the parameter is obtained. For multiple partially synthetic datasets, Reiter (2003) proposes a different formula to obtain the total variance estimate given the within-set variance and between-set variance estimates from multiple sets.
As is the case for the data synthesis without differential privacy, when analyzing and obtaining valid statistical inferences from differentially private synthetic data, it is important to consider the uncertainty arising through the differentially private data synthesis procedure. Compared to data synthesis without differential privacy, the uncertainty comes from one additional source, namely the noise infusion mechanism employed to achieve differential privacy guarantees on top of the synthesis uncertainty and sampling error of the synthesis data. There are a couple of approaches to account for the uncertainty in the literature.
First, one may incorporate the differential privacy sanitization and data synthesis process directly when modeling and analyzing the synthetic data (Charest, 2011; Karwa et al., 2017; Nixon et al., 2022; Seeman et al., 2020). This approach can be demanding for data users either analytically or computationally. The second approach is to release multiple synthetic datasets, similar to the multiple synthesis approach without differential privacy. Liu (2022) provides several schemes for multiple synthesis with differential privacy and an inferential rule for combining inference across multiple sets, which turns out to be the same rule used by Reiter (2003) for partial synthesis with differential privacy. Due to the extra source of variability from the usage of randomized mechanisms for achieving differential privacy guarantees, inferences from the differentially privately synthesized data are generally less precise than those from multiple synthesis approaches with differential privacy—a price paid for formal privacy guarantees. If the multiple synthesis approach is adopted, it is important to be careful regarding the choice of the number of datasets to synthesize and release in the differential privacy setting.
In multiple synthesis with differential privacy, the number of synthetic datasets is mainly driven by computational time and storage considerations, and a small number of datasets (e.g., 5 to 10) would be preferred in practice, as long as the number is large enough to capture the between-set variance and deliver valid inference. In contrast, in the differential privacy setting, the decision on the number of synthetic datasets is driven more by the utility of synthetic data at a prespecified privacy budget. Due to privacy loss composition across multiple releases, each synthetic set receives only a portion of the total budget. If the number of sets is too small, the released information may not be sufficient to capture the between-set variability; but a too-large number risks spreading the budget too thin across the sets, and each synthetic set would be so heavily perturbed that aggregating information across the multiple synthetic sets would not remedy the information loss. Tran et al. (2023) perform an empirical study on the budget allocation on their proposed differentially private synthesizer for the synthetic LBD. The U.S. Census Bureau has done such privacy-loss and accuracy evaluations for the budget determination with their TopDown Algorithm (Abowd et al., 2022).
STATISTICAL EVALUATION OF DATA UTILITY
A key consideration in adopting any data synthesis approach is the statistical validity of inferences constructed from synthetic data. This validity can be assessed by applying a set of specific analyses to a list of statistics, such as point estimates, interval estimates, and statistical-significance-of-hypothesis testing results, and for general utility without focusing on any specific analysis.
A straightforward metric for evaluating the similarity of a statistic calculated from the synthetic data and one derived from the original data is to calculate the absolute deviation, squared deviation, or maximum deviation of the former from the latter. This type of metric is often not inference-based, and it does not take into account the uncertainty around the statistic, but rather it focuses on how much the synthesis process deviates the statistic from its original value.
Another option is to use a propensity score analysis, in which the original and synthetic data are appended and compared, treating the original as “control” observations and the synthetic as “treated” observations. This approach then checks for balance in the covariate distributions across the two datasets. The empirical distributions of the propensity scores can be compared for the original and the synthetic records separately. A similarity metric between the original and synthetic data can also be computed (Arnold & Neunhoeffer, 2021; Bowen & Liu, 2020; Sakshaug & Raghunathan, 2010; Snoke et al., 2018; Woo et al., 2009).
To assess the validity of statistical inferences, one can develop a large set of candidate analyses from the published literature or as suggested by a panel of SIPP users, and then compare the statistical significance of hypothesis testing results and interval estimates obtained from synthetic and original datasets. Karr et al. (2006) propose the confidence-interval overlap metric to compare interval estimates from the original and synthetic datasets. A value of 1 in this metric corresponds to a perfect match between the two confidence intervals (based on the synthetic and original data); a value of 0 means there is no overlap between the two confidence intervals, regardless of how far these two confidence intervals are separated. When one confidence interval is completely contained within the other, the value of the confidence-interval overlap is greater than 0.5.
Eugenio and Liu (2021) propose the “SSS” assessment. The first S refers to the sign of the point estimate, and the second and third S’s refer to the statistical significance of the estimate. Based on the consistency in the sign and statistical significance for the estimates from the original and synthetic data, seven categories are formed, ranging from “the best,” meaning matching in both sign and statistical significance, to “the worst,” meaning matching in statistical significance but not in sign. Between the two extremes, there are five categories, representing different types of mismatching on sign or statistical significance. Stanley and Totty (2021) also compare the statistical significance results of estimates based on original and synthetic data.
Bowen and Snoke (2021) conducted an in-depth analysis on the statistical utility of the generated synthetic data of differential privacy guarantees in the Differential Privacy Synthetic Data Challenge sponsored by National Institute of Standards and Technology Public Safety Communications Research in 2019. There were three matches on three different real datasets
in the competition in which different teams competed against one another.8 Synthetic data were generated for different levels. The conclusion from this competition was that differentially private data synthesis algorithms that used preprocessing and budget allocation based on public information and subject matter utility criteria performed better. The overall best performer used a distribution-free approach, synthesizing data from a predetermined set of low-dimensional histograms/contingency tables (McKenna et al., 2021). Though this was a data challenge event, all three matches used real data, so the competition results and the subsequent analysis of different approaches are insightful in terms of the feasibility of differential privacy synthetic data generation in practice.
Validation and Verification Systems
The validity of the inferences rests on the synthesis model, and therefore a robust validation and verification system is important for assessing the quality of the inferences obtained from the synthetic data. Toward that end, an interactive and web-based system can be developed so that data users can query for measures to check the quality of their analysis results and to learn whether the conclusions suggested by the results are correct or not with a certain level of confidence (Vilhuber, 2019).
Figure 6-4 illustrates how a validation server works. In brief, data users perform analysis on synthetic data and obtain some results. Before publishing the results, they want to validate the quality of the results and gain confidence in their conclusions, so they send their code to the validation server, which runs the code on the confidential data. Releasing quality measures to queries submitted by data users to a validation system incurs disclosure risks due to the fact that information based on the confidential data is being shared with these users. To resolve this, the results sent back to the users can be made private through some privacy-protection mechanisms, such as ones with differential privacy guarantees. After the users receive the privacy-protected results from the server, they can compare them with their own results based on the synthetic data. They can then make a decision about publishing either their synthetic data results or privacy-protected results from the server.
The Urban Institute has developed a prototype of an automated privacy-preserving validation server that allows users to submit their code and run it on the confidential data, which then returns privacy-protected noisy results with differential privacy guarantees (Taylor et al., 2021). The motivation behind the project is to speed up the validation process
___________________
8 The training datasets are large in size (236,000, 314,000, and 210,000 to 662,000) with a mixture of 32, 32, and 98 categorical and numerical variables in each.
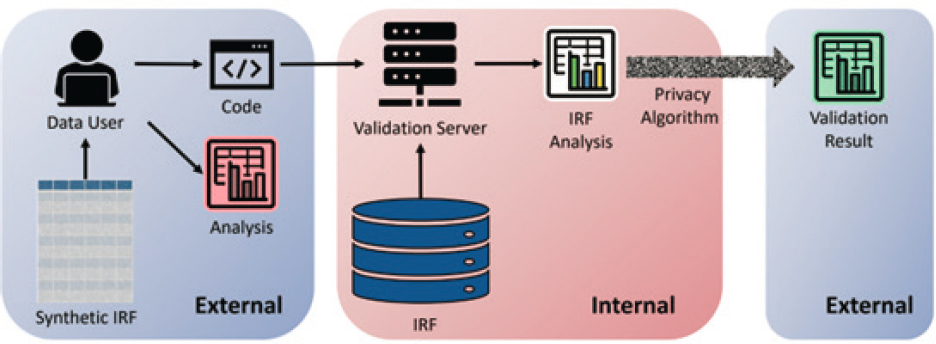
NOTE: IRF stands for “internal reference file”; internal refers to the agency that collected and provided the data; external refers to data users.
SOURCE: Gary Benedetto and Rolando Rodriquez, presentation to the panel, June 30, 2022. See also https://www.urban.org/research/publication/privacy-preserving-validation-server-prototype
by automatically reviewing queries and generating privacy-protected results that are to be shared with users. Compared to manual clearance and manual review, this automated system would save time, manpower, and resources. Since the server is a prototype and “built to the minimum standards for testing,” it currently runs only tabulation queries on the Internal Revenue Service (IRS) Statistics of Income Public Use File.
Unfortunately, while the Urban Institute project may be a partial prototype, it is not yet completed and SIPP data are considerably more complex. It may not be possible to develop a validation and verification system that accommodates every possible analysis of SIPP data, particularly considering the complexity of both the data and the data analyses that are commonly pursued. Such a system is desirable from the user perspective and for limiting the burden on the Census Bureau, but developing a complete system is at best a long-term project. Creating secure online data access (SODA) with easy access is imperative when a user who is unable to use the verification and validation system can avail him- or herself of SODA to perform the analysis and submit both the results for possible validation and verification.
In addition to validation servers, it is also important to provide users with clarity regarding the models, algorithms, or techniques employed for generating synthetic data so that users have some knowledge in advance about which relationships are likely to have been preserved and which are not. Extensive accuracy testing of the type described in the previous section will, ideally, be conducted by the Census Bureau prior to its release of a synthetic dataset to the general user community. This will save both the Census Bureau and the user unnecessary effort and resources devoted to relationships that may not be preserved. The user community will want to be assured that particular relationships are preserved and to be able to trust that assurance.
Besides validation servers, there are also verification servers, which are related to but different from validation servers. Reiter (2023) defines a verification server as follows. Data users submit a query to the verification server on some statistical analysis. The server performs the analysis on both the confidential and synthetic data and the server calculates “analysis-specific measures of the fidelity of one to the other” (e.g., the overlap of the 95% confidence intervals for a parameter when computed on these two data sources [Karr et al., 2006]). The server then returns the value of the verification measure to the analyst. The analyst can decide, based on the feedback, whether the synthetic data have high utility for the analysis. Barrientos et al. (2018) apply the server integrated approach of synthetic data generation plus verification to longitudinal data on employees of the U.S. federal government and are able to show that the integrated system performs as intended, allowing users to explore the synthetic data and verify their findings by querying the verification server.
In summary, with a validation server the agency runs the user’s statistical analysis on the confidential data and returns to the user a privacy-protected version of the results. With a verification server, the agency runs a user’s statistical analysis on both the synthetic and confidential data and returns values on verification measures, which may also be made privacy-preserving if the measures leak privacy.
SIPP SYNTHETIC BETA (SSB)
SIPP is one of the few major federal surveys that has attempted to produce a synthetic dataset for privacy protection. The creation of the SSB data file was not motivated by general privacy concerns about the public-use SIPP data files but rather by the desire to add administrative data on earnings and Social Security benefits to SIPP survey files. The addition of those data aimed to address well-known problems of misreporting of those variables in household surveys, including in SIPP. However, administrative data on earnings are highly sensitive, and both legal restrictions and interagency agreements prevent the release of Social Security Administration (SSA) and IRS data, so the Census Bureau chose to follow the synthetic data approach to make that information available to SIPP users (the data are also available in Federal Statistical Research Data Centers).9
There were two steps in the creation of the SSB. The first step was to merge administrative data on earnings and benefits from the IRS and from the SSA onto the internal SIPP files at the Census Bureau, using a Protected Identification Key to match the administrative records to the survey records. This file was dubbed the Gold Standard File. Second, using a sequential regression multiple synthesis approach (like the one discussed earlier in this chapter), the joint distribution of the administrative data and a relatively small number of SIPP survey variables (a little less than 100, out of the approximately 2,900 on the SIPP public-use file) were modeled. Random draws from the posterior of that distribution were made to create implicates for the user to analyze. Together with the administrative data, the SSB file has approximately 140 variables. The SSB file is fully synthetic in the sense that all variables in it are synthesized by the model.10 The latest version of the SSB has survey information from nine SIPP panels, covering a period from 1994 to 2008 and containing the additional variables for administrative data on earnings and benefits, namely historical earnings that go back to the 1950s. It should be emphasized that the administrative data on
___________________
9 See Chapter 2 for additional discussion of the SSB.
10 This means that the SSB does not have the potential problem of uncongeniality noted later in this chapter. There are no variables in the SSB file that are not in the data-generating model.
earnings contain the entire lifetime history of earnings for any individual who participated in any of the SIPP panels, so those variables cover a far longer period than the survey data themselves.
One of the important issues in any synthetic dataset, as the panel will discuss further in this chapter, is whether all relationships among the synthesized variables in the original file are preserved in the synthetic file. Preserving those relationships is likely to be difficult for a dataset with 141 variables, and especially so considering that those 141 variables are observed multiple times for each individual, because the SSB, like SIPP itself, is a panel. For all relationships to be preserved, the joint distribution of the 141 variables at multiple points in time must be preserved, not just their cross-sectional distribution at each single point in time. Again, from the perspective of a user, if not all relationships have been preserved it is important to know which ones have and which have not.
However, while the general structure of the modeling effort has been published by the Census Bureau (Abowd et al., 2006; Benedetto et al., 2013; Benedetto et al., 2018), the details of the model—what variables are used and how they are used—have not been made available to users for confidentiality reasons. This makes it difficult for users to know which relationships in the SSB are likely to be accurate reflections of the Gold Standard File and which are not. The Census Bureau allows users—indeed, strongly encourages them—to submit their programs to the agency to run on the underlying Gold Standard File data, with the output returned to the user to check against the results they obtained with the SSB. This is an example of a validation server, as discussed above, and allows the user to ensure the accuracy of their results. However, as noted in Chapter 2, the statistics on requests for validation appear to suggest that some users do not submit their programs for verification; it is not required. Also as described in Chapter 2, to date there have only been just over 200 users of the SSB and, in fact, it has temporarily ceased operation as of this writing. Given the laborious involvement of the Census Bureau in running user programs for every validation request, it is unlikely that far greater numbers of users could be accommodated by Census Bureau staff to conduct more requests with their current staffing.
To assist users to know in advance which relationships have been preserved in the SSB and which have not, analysts at the Census Bureau have also conducted analyses to determine the accuracy of at least a few use types. Stanley and Totty (2021, 2023) conducted a number of comparisons of the SSB to the Gold Standard File, concentrating on the earnings data since they were the main variables motivating the creation of the SSB. Their study showed that the shapes of the earnings distributions in the two datasets were roughly the same, but not exactly, and there were some differences in the tails of the distributions. Median earnings were quite close in the
two datasets, but mean earnings were somewhat different. The correlation of earnings with demographic variables were roughly the same in the two datasets and tended to follow the same trends over time. However, some estimation models using quarter of birth differed in the datasets, and differences between the SSB and Gold Standard File were found when state-level data on the minimum wage (which are external to the SSB) were merged onto the SSB and used for a common statistical model used for SIPP by researchers. The authors attributed this finding to the synthetic data model, which they said did not capture such relationships.
A second study, by Carr et al. (2023), compared the SSB to the Gold Standard File for an analysis of what is called earnings volatility, which measures how much individual earnings are or are not stable from one year to the next. The authors found that the levels of volatility in the SSB were quite different than those in the Gold Standard File for many (but not all) measures, and also found that both the cross-sectional variances and the covariances between earnings in different years were different. However, many of the relationships between demographic variables were similar, and the patterns over time were similar. Coupled with the Stanley and Totty studies just referenced, it appears possible that the SSB is not correctly capturing the relationship between an individual’s earnings in different time periods of the SIPP panel (sometimes called “earnings dynamics”) and, more generally, is not capturing the evolution of an individual’s earnings over time.
Expanding on this experience, the Census Bureau can explore more use of synthetic data to release many variables that may be deemed disclosive. While the purpose of the SSB was to supplement SIPP data with external data, rather than to protect SIPP survey data, experience with the SSB is instructive for how synthetic data might be approached. Several approaches may be considered. The panel outlines possible strategies for SIPP data next.
CHALLENGES IN SIPP DATA SYNTHESIS AND UTILITY EVALUATION
As introduced in Chapter 2, SIPP is longitudinal (responses are taken from the same individual at multiple time points in the survey), high-dimensional (it reflects thousands of responses collected from the same individual), and multimodal (containing different data types—numerical, categorical, relational). In addition, SIPP data are collected using a complex survey design, with different sampling weights for different individuals and separate weights for different types of analyses; the final panel weights for SIPP 2020 range from 387 to 39,951 (see Chapter 2). On top of the inherent complexity of the data, SIPP data are also subject to high nonresponse rates on various variables, leading to a large portion of missing values in the collected data.
While there is a rich body of literature on data synthesis techniques, both with and without differential privacy, and some of these techniques have been applied to releases of real data, many of the techniques deal with only one or a couple of the characteristics of SIPP and none deal with all of them. In addition, many techniques, including the recent generative models rooted in deep neural networks, are developed with an explicit or implicit assumption of simple random sampling, do not have missing data, or have difficulty scaling up to the case when there are thousands of attributes in a dataset. If differential privacy is factored in, the usefulness of the synthetic data could further degrade.
Given the variety and the large number of response variables in SIPP, it would be a daunting task to synthesize all the variables (quasi-identifiers and responses) in the data. If some of the collected response variables are unlikely to be released for either research or public use, they can be kept in-house but be conditioned on synthesis models for generating synthetic data for other variables. For the rest of the variables, it is important to consider the tradeoff between disclosure risk and the utility of the synthesized data in each case.
As suggested above, uncongeniality between the synthesis model and the analyst’s model is a common challenge in partial data synthesis approaches. If the synthesis model is not expansive enough, inferences based on the synthetic data for the analyst’s model will be biased. For a partially synthetic SIPP file with synthesized sensitive variables but a large number of unsynthesized quasi-identifiers, depending on which attributes are released and what the analyst’s models are, the uncongeniality issue can be serious. On the other hand, a synthesis model being more expansive increases the likelihood that the model will overfit the original data, which may be associated with higher disclosure risk. Finding the right balance between data utility and disclosure risk limitations will be important.
Finally, the variety of the types of analysis that can be performed on the rich SIPP data also makes it difficult to assess the utility of synthetic data. The particular set of analyses selected to compare synthetic data with the original SIPP will be important if one is to have confidence in the reliability and usability of the synthetic data. The panel suggests that utility be evaluated in light of the three unique contributions of SIPP in comparison with other datasets, as described in Chapter 2: its large number of variables describing characteristics of U.S. individuals and households, its high level of detail on social program participation, and its longitudinal nature, which allows it to follow individuals and households over time and chart the evolution of their socioeconomic status.
There are several alternative approaches to synthetic data files that the Census Bureau could consider. While a fully synthetic longitudinal SIPP
would be difficult, as discussed above, a partially synthetic file that retains a large number of unsynthesized variables is worthy of consideration. The usefulness of such a file would depend on how many unsynthesized variables can be put on a public-use file, and that question can only be answered by running more re-identification analyses, as recommended in earlier chapters. In addition, disclosure risk would have to be carefully assessed in the release of any such file. An alternative approach is to release synthetic data files separately from the public-use file, containing sensitive variables. This is the approach currently taken by the SSB. However, those synthetic files would necessarily also need to retain a number of the quasi-identifiers in the public-use file, although they could be synthesized (as they are, again, in the SSB).
It is also possible that the Census Bureau could construct and release multiple synthetic files, each containing a different set of synthesized synthetic variables. However, because these would each have to have a set of quasi-identifiers that would likely overlap one another as well as overlapping the public-use file, it would be necessary to assess the disclosure risk from an intruder combining all the synthetic files with the public-use file, which would be a challenging assessment to carry out.
Additionally, a synthetic data approach may also be used as a viable method for providing data from outside of SIPP, similar to what was accomplished with the SSB.
CONCLUSIONS AND RECOMMENDATIONS
Conclusion 6-1: Data synthesis is a well-established framework for disclosure limitation, and many techniques have been developed for both fully and partially synthetic data generation, including some that use formal privacy guarantees. Data synthesis may be a useful approach for protecting data in a new tier of access.
Conclusion 6-2: The Survey of Income and Program Participation (SIPP) Synthetic Beta effort may be regarded as a pilot effort that has tested the reliability and usability of a small synthetic dataset drawn from SIPP. Its success to date has been mixed. Its use has been limited, and it has also demonstrated the need for an automated verification and validation server. The SIPP Synthetic Beta placed a considerable burden on the Census Bureau to manually verify results, and not all synthetic results were confirmed.
Conclusion 6-3: State-of-the-art machine learning frameworks, when combined with the increasing amounts of public data and information that are becoming available, are likely to increase the privacy risks
associated with synthetic data. Traditional synthetic data generation may no longer be sufficient for privacy protection. Data synthesis with formal privacy guarantees can be more effective in frustrating privacy attacks.
Conclusion 6-4: Differentially private data synthesis provides an approach to generating synthetic data with formal privacy guarantees following a prespecified privacy budget. Compared to traditional data synthesis approaches, additional calibrated noise is introduced to meet the prespecified differential privacy requirement.
Conclusion 6-5: Inferences based on differentially private synthetic data are subject to all sources of variability, including the sampling error of the original data, uncertainty due to synthesis, and noise introduced by randomized algorithms for achieving differential privacy or other privacy criteria.
Conclusion 6-6: When releasing synthetic data, it is important to evaluate the similarity of inferences using general purpose measures to assess data utility and usability. Assessment of the validity of inferences based on synthetic data is multifaceted and requires comparison of point and interval estimates and hypothesis testing results, across a wide range of use cases.
Conclusion 6-7: It is important that the way synthetic datasets are constructed be transparent to the user and that the user be enabled to understand the relationships that are preserved and the relationships that are not preserved in order to have trust in the data. The user community will benefit by being informed in this way prior to the release of the synthetic dataset. Validation and verification servers can also be used to help build trust by allowing the users themselves to determine which relationships are preserved and which are not.
Conclusion 6-8: Automated verification and validation servers would provide synthetic data users with a platform to check the quality of their analysis results based on synthetic data and to have confidence in their findings, while saving resources as compared to the use of verification and validation servers that are manually maintained.
Conclusion 6-9: There is currently no off-the-shelf approach for generating reliable synthetic data for a survey as complex as the Survey of Income and Program Participation, with or without formal privacy metrics.
Recommendation 6-1: The Census Bureau should support research that develops new approaches and techniques for generating synthetic data and assessing data utility and disclosure risk, with or without differential privacy or other privacy guarantees, and should fund work that creates and updates tools and systems that evaluate synthetic data, disclosure risk, and usability and collect data users’ feedback.
Recommendation 6-2: The Census Bureau should develop a systematic protocol and a set of metrics for assessing and measuring the validity of inferences constructed from synthetic data.
Recommendation 6-3: To support the use of synthetic data, the Census Bureau should develop a routine automated system to perform user-submitted analyses on the internal file and send the results back to the user after they have been treated for disclosure avoidance.
Recommendation 6-4: The Census Bureau should consider creating partially synthetic datasets to allow analyses of sensitive or disclosive Survey of Income and Program Participation survey data variables that are not on or may need to be dropped from the public-use file. These synthetic variables might be added to the public-use file in place of the original variables.
This page intentionally left blank.























