Implementing Machine Learning at State Departments of Transportation: A Guide (2024)
Chapter: 2 Roadmap to Building Agency Machine Learning Capabilities
CHAPTER 2
Roadmap to Building Agency Machine Learning Capabilities
Overview of the Roadmap
This guide adopts the high-level roadmap in Figure 1 as a framework for building agency ML capabilities, starting with an ML pilot project. The roadmap consists of 10 steps and includes a loop from Step 5 to Step 2 to emphasize the iterative nature of the ML development and implementation process. This roadmap is broken down into 10 steps:
- Step 0: Develop Understanding. Develop an understanding of ML key concepts and applications in transportation. This step summarizes what is needed to develop an ML model, highlights differences between ML and traditional methods that agencies are familiar with, and summarizes core and emerging ML concepts. It also includes examples of how ML has been used successfully in transportation so far as well as a discussion of ML techniques expected to impact transportation in the near future, such as large language models (LLMs). It is labeled as “Step 0” for two main reasons: (1) it assumes some agency staff may already understand the basics of ML, and (2) in true data scientist fashion, the roadmap is indexed at zero.
- Step 1: Identify Use Cases. Identify candidate transportation use cases where ML could support agency needs. This step discusses primary ML capabilities useful for transportation use cases (i.e., detection, classification, prediction) and includes examples of the types of transportation problems that can potentially be solved by ML methods, drawing on agency success stories and the literature.
- Decision Gate #1. After getting a sense of the landscape and possibilities of ML, the agency is faced with its first major decision gate: is ML a suitable approach for one or more of our agency’s needs? If so, in what capacity? This decision gate includes a checklist to help agencies decide whether ML is a feasible and desirable approach for one or more of their needs, based on the main criteria of suitability and maturity and their assessment of candidate transportation use cases.
- Step 2: Assess Gaps. Assess the availability of current resources to support ML and any gaps, including data, data storage, computing, workforce and organizational considerations, funding, and other considerations, including privacy and policies.
- Step 3: Build Business Case. Build a business case to secure leadership buy-in. This step discusses best practices in building a case for leadership to pursue an ML pilot project to support broader agency capabilities. It also includes information on identifying the value proposition of leveraging ML, including potential benefits and return on investment (ROI), as well as spreading awareness of uncertainties, potential risks, and costs to different stakeholder audiences.
- Decision Gate #2. The agency team will need to decide if and how to plan an ML pilot project given the resource availability and gaps identified in Step 2 and the leadership appetite from Step 3. If a “go ahead” decision is made, options may include executing the entire ML pipeline and developing all code in-house, leveraging available open-source code and applying it to
- the identified use case, or acquiring proprietary services, data, software, and/or consulting to support one or more aspects of the pilot. This step includes important questions to help teams decide which option to pursue for the pilot and summarizes the different benefits and risks of each approach.
- Step 4: Plan Pilot. Plan the ML pilot project, including the pilot scope, schedule, and budget. This step includes a detailed hypothetical example of pilot scope planning for a transportation asset management use case. It also includes important best practices, lessons learned, and examples concerning pilot schedule and cost considerations.
- Step 5: Execute Pilot. Execute the ML pilot project, including one or more aspects of the ML pipeline if the agency plans to build a custom model. During pilot execution, the agency may discover they need more data or other supporting elements for the project to improve model performance or system integration. Therefore, the roadmap incorporates a loop back to Step 2 to illustrate this iterative process.
- Step 6: Communicate Results. Communicate the results of the ML pilot. At this stage, the team should share the results of the pilot project, including relevant evaluation metrics, with others across the agency to spread awareness and build buy-in.
- Step 7: Scale Deployment. Scale from a pilot to a larger deployment. If the pilot project demonstrates promising results, it can be scaled by location, time, user base, and/or scope into a larger deployment.
- Step 8: Operations & Maintenance. Conduct operations and maintenance (O&M) of the newly deployed system. It may be helpful to assign one or more team members to be responsible for overseeing regular O&M for the ML application, which includes monitoring the input data and the ML model’s performance for signs of drift. Additionally, it is crucial to consider the deployed system’s lifecycle costs and secure ongoing funding to ensure it keeps operating smoothly.
- Step 9: Expand ML Capabilities. Continue to expand ML capabilities across the agency. This includes building out a broader enterprise AI/ML strategy and enterprise data management strategy, building workforce capabilities and training staff, fostering a data-driven culture at the agency, and collaborating within and across agencies.


Step 0: Develop Understanding
Introduction to ML Approach
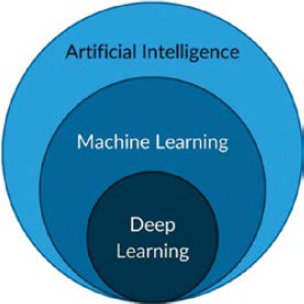
ML is a subfield of AI (Figure 2) that encompasses a wide variety of methods, ranging from simpler models like decision trees to DL or complex neural networks (NN) with billions of parameters. ML models fundamentally learn from data or examples. Rather than relying on explicit programming, ML models discover complex patterns through a model training process. Their applications include extracting insights from data, finding correlations among variables, predicting likely outcomes from given inputs, finding optimal strategies for decision-making, and so forth. Furthermore, ML models can adapt to new data and improve their learning over time without human intervention, which makes them effective for complex tasks where conventional algorithms might not be feasible.
While simpler models such as decision tree learning are considered part of ML, they prioritize interpretability and understanding of relationships between variables, whereas more complex models (e.g., deep NN) focus on predictive accuracy. One could even argue that linear regression is a rudimentary form of ML; however, this text compares classical models, such as linear regression, to more complex ML models. When referring to ML in this text, we are referring to these more complex techniques unless otherwise indicated. ML models, primarily those based on deep NN, have evolved rapidly within the last 10–15 years, with breakthroughs in image processing and recognition. Advanced deep NN architectures can now outperform humans in various board and video games as well as image and object recognition (Silver et al. 2017; Purves 2019; Payghode et al. 2023). These advancements rapidly catalyzed applications of AI/ML in almost all industries, including transportation.
ML models differ from more traditional statistical learning models in their approach to solving problems. In traditional statistical learning methods, the focus is on understanding relationships between variables or making inferences about some parameters of interest, whereas in ML the prediction accuracy is the central notion. ML models are designed to make the most accurate predictions possible when given new data – data not used in training the model. The model

training process involves finding the best set of parameters that will produce the most accurate results when applied to new data. Complex ML models, such as deep NNs, generally improve their predictive accuracy when provided with larger datasets. More technical details about the development process of ML can be found in the discussion of Step 5 in this guide.
Figure 3 shows several key aspects distinguishing ML models, especially complex deep NNs, from more traditional models (e.g., linear regression). These aspects include the following:
- Learning from data: Traditional models start by assuming a fixed form (e.g., a linear relationship) and attempt to find relations in the data matching the assumptions. On the other hand, ML models can adapt to nonlinear relations and trends present in the data and learn them during the model training process. Since ML models learn from data, the same model structure could be applied to a wide variety of problems. More information about learning from data is provided in the next section.
- Adapting to new data: As new data become available, ML models can adapt and change their parameters to capture new patterns and trends in the data. In traditional models, the user selects certain salient features (e.g., data attributes) manually. On the other hand, modern ML models [e.g., convolutional NNs (CNNs) and DL models] learn the most useful features automatically during the training process. This provides a significant advantage over traditional models. As the input data vary over time, these features may vary as well. ML models can adapt to new data by capturing such new features and optimizing their parameters in a (re)training process. Through iterative retraining, ML models can maintain their relevance and predictive accuracy over time as the data changes.
- New insights and solutions: Another important benefit of ML models is their capacity to uncover new insights and solutions that might not be easily discovered by experts. ML models are particularly adept at searching through complex data and identifying patterns and correlations that might not be obvious with traditional analysis. Traditional models often involve prior hypotheses and have predefined structures, which may limit their adaptation or learning from the data. The capabilities of ML models have been demonstrated in various diverse fields.
- In gaming, ML algorithms (e.g., AlphaGo) have devised strategies and moves that were previously unexplored by human players, while in drug discovery, ML models have identified previously unknown compounds with therapeutic potential. In the transportation field, ML models developed for self-driving vehicles can recognize objects, make real-time decisions, and navigate complex environments without the need to explicitly preprogram all possible scenarios.
- Ability to learn from high-dimensional complex data: ML models are effective in learning to make accurate predictions even if the data are complex and high-dimensional, which means the data have many input features. They employ iterative processes and algorithms that can detect patterns, make decisions, and improve over time. ML models extract the most informative features and reduce the complexity of the raw data using different types of techniques (e.g., Principal Component Analysis [PCA] or autoencoders). The best model parameters are found through optimization algorithms (e.g., gradient descent) that can handle high-dimensional search. ML models are found to be effective in handling large and diverse sets of video/image, computer code, point cloud, text, speech, geospatial, and other kinds of data.
Learning from Data
A fundamental aspect of ML is learning from data without the need to specify explicitly what and how data features should be used by the algorithm. For example, deep NN can capture complexities in the input data and recognize useful patterns if trained with sufficient data. In general, more data translates to more accurate predictions and robust models. In the transportation field, vast amounts of data with complex relationships have become increasingly available in recent years because of the proliferation of sensors and automatic data collection systems (e.g., connected vehicles data, condition monitoring sensors). There is a large body of academic studies on how ML could provide value in processing and leveraging such data. For more information, see Chapter 1 of NCHRP Web-Only Document 404: Implementing and Leveraging Machine Learning at State Departments of Transportation (Cetin et al. 2024), a conduct of research report that documents the development of the guide and the entire research report, available on the National Academies Press website (nap.nationalacademies.org) by searching for NCHRP Research Report 1122: Implementing Machine Learning at State Departments of Transportation: A Guide.
Various types of learning paradigms have been proposed based on data availability and the intended outcome of the ML model. Depending on the use case, the learning structures include supervised, unsupervised, and reinforcement learning. These learning types are distinguished based on the relationship between the input and output and the way the ML model interacts with the training data. If both input and output (also referred to as “labels”) are used to train the ML model, the structure is referred to as supervised learning, in which case the ML model learns the relationship between the input and given output. The algorithm “learns” by going through examples in the dataset and by trying to find patterns or rules that connect the input data to their corresponding output (or labels). After the algorithm learns, it can take a new, unseen piece of input data (e.g., a new image of a vehicle) and predict the output (e.g., correctly identify the class of vehicle in the image). In the model training process, the model adjusts its internal parameters to improve its predictions based on the examples it has seen. After training, the model is tested with a new set of data it has not seen before, a process called model validation. If the validation results are satisfactory (e.g., accuracy levels meet the expectations) the model could then be considered for implementation. Supervised learning is the predominant type of learning in most ML applications.
If the input data do not have an associated output, unsupervised ML models can be used to extract possible patterns and cluster the input data based on similarities between the attributes of the different data points. For example, speed data coming from connected vehicles (CVs) may

contain multiple clusters because of variations in vehicle types (e.g., trucks versus passenger cars) or traffic conditions (e.g., congested versus uncongested). If the conditions under which the CV data are collected are unknown in this example (e.g., vehicle types are unknown), and clustering of the data is desired, unsupervised ML models could be employed to identify such patterns in the data. These models analyze the observations and cluster data points exhibiting similar characteristics in the same group.
Reinforcement learning (RL) is a different learning process, in which the machine (or agent) learns from interacting with an environment and the consequences of its actions (Figure 4). For example, through a trial-and-error process, an RL algorithm can learn how to best time a traffic signal if provided with a simulation environment and a goal. The goal (more technically the reward function) can simply be minimizing total delays. In this form of learning, the purpose is to find the best policy that will optimize a reward function. The policy in this context would be determining the signal timing parameters (actions) for a given set of traffic volumes (system states). RL methods are suitable for determining the optimal solutions to sequential decision problems. While there are many academic articles on potential RL applications in transportation (see Chapter 1 of Cetin et al. 2024), examples of practical applications of RL methods at state DOTs are hard to find.
Trends in Machine Learning
The ML landscape is evolving rapidly and is driven by advancements in algorithms, computational power, and the availability of large datasets. Recently, applications built on top of large language models (LLMs), such as OpenAI’s ChatGPT and Google’s Gemini, among many others, have gained significant attention and made it possible to perform many tasks without the need for coding expertise. These publicly available models operate with billions of parameters and are trained on vast amounts of data. This makes it possible to perform high accuracy on an extensive range of language-related tasks. These generative AI models are becoming more powerful for numerous applications, including conversational interactions and generating text, video, and computer code. These models could support various agency operations, including summarizing and analyzing large documents and helping staff with coding or creating Excel formulas. However, they have also raised many ethical concerns, such as those regarding ownership of the created content and compliance with copyright laws. Despite their impressive capabilities, it is important to note that these models are not error-proof and can still generate inaccurate results and information. The following callout box shows the response from ChatGPT to a question on the top three strengths and weaknesses of ML.
As the ML landscape evolves, the implementation of ML to solve real-world transportation problems will evolve as well. For example, the level of effort needed for model training may diminish in the future as more robust multipurpose pre-trained models become widely available or
![]() Response 1
Response 1
Certainly, here’s a more concise summary:
Strengths:
- Pattern Recognition: Efficient at identifying patterns in data.
- Automation: Automates complex, repetitive tasks.
- Adaptability: Improves with more data over time.
Weaknesses:
- Data Dependency: Requires large, quality datasets.
- Lack of Explainability: Often operates as a “black box.”
- Resource Intensive: Needs significant computational and expert resources.
the norm. Important trends will likely impact how ML solutions are procured and deployed by transportation agencies in the future. Some of these include the following:
- Automated machine learning (AutoML) and machine learning as a service (MLaaS): AutoML and MLaaS offerings are making ML more accessible to non-experts. These are expected to increase the usage of ML since the need for expertise and a skilled workforce will be minimized.
- Algorithmic Innovations: New ML algorithms and architectures, particularly in deep learning, are being developed at a rapid rate. Innovations like attention mechanisms, transformers, and generative adversarial networks have opened new possibilities in areas such as natural language processing (NLP) and synthetic data generation. These innovations help create new models (e.g., large language models) that can solve a broad range of problems.
- Data Availability: ML models thrive on large datasets, and the increasing availability of big data has been a significant driver of ML progress. As more transportation data become available and more ML models are developed and tested, such models are expected to become more widely available and accessible to agencies.
- Cloud Computing: Deploying ML models on the cloud platforms allows access to the necessary computational resources and alleviates the need to invest in expensive infrastructure.
There are numerous resources on ML, including online courses, tutorials, sample codes and notebooks, research papers, books, and so forth. The AI Primer published by the Transportation Research Board Committee on Artificial Intelligence and Advanced Computing could be a good starting point for an overview of ML; see https://sites.google.com/view/trbaed50/resources/primer?authuser=0.
Interpretability of ML Models
It should be noted that some ML models are criticized as being “black boxes” because of the lack of transparency in how they generate their outputs. For applications where model explainability and/or interpretability are critical (e.g., because of regulatory compliance), complex ML models may not be suitable. Explainability and interpretability are closely related concepts. Interpretability is about the clarity of a model or the degree to which a human can understand
the cause of a decision and the inner workings of the model. A decision tree is considered interpretable because its decision-making process is clear and can be followed step-by-step. On the other hand, explainability is focused on explaining the decisions made by complex ML models (e.g., deep NN). Various methods are developed to make the ML model’s outputs explainable, even if the inner workings of the model are complex and opaque. In other words, other models are built to explain complex ML models. For example, through visualizations of what the model is focusing on when making decisions, or post-hoc explanations for specific decisions, the user may be able to understand the links between inputs and outputs produced by the ML model. The field of explainable artificial intelligence deals with creating methods to explain and reveal such links.
Generally, there is a trade-off between a model’s performance (e.g., its prediction accuracy) and the degree of explainability or interpretability – high-performing models tend to be more complex and, hence, have lower interpretability. Figure 5 shows this trade-off and lists sample ML models with different levels of complexity and interpretability. When considering an ML application in transportation, the need for model transparency needs to be assessed, and ML models meeting these needs should be selected. For applications where explainability is not critical but accuracy is, such as detecting pavement cracks from image data, complex models such as deep NN would be appropriate.


Step 1: Identify Use Cases
ML models are useful for performing various types of tasks. With the proliferation of deep learning methods and the availability of large datasets, ML models have been proven to be very effective in key image processing tasks including object detection (identifying objects within images), classification (e.g., categorizing images into classes), and semantic segmentation (labeling every pixel in an image according to its category). Numerous ML/DL applications have been built over the last decade across all major sectors addressing various needs and leading to transformative impacts. Such examples include drug discovery and medical image analysis, fraud detection in financial data and credit scoring, driving assistance systems in autonomous vehicles, content creation tools for arts and entertainment sectors, climate modeling, and more.
According to the survey conducted as part of the NCHRP 23-16 project, at least one respondent from 15 of the 29 states represented in the survey indicated that their agency had ML applications currently deployed and/or being developed. These agencies have implemented ML solutions for various applications, with transportation systems management and operations (TSMO) and asset management being the most common. The NCHRP 23-16 conduct of research report also presents a summary of the ML state of the practice that was based on nearly 70 identified ML-related projects involving agencies (see Chapter 1 of Cetin et al. 2024). Based on this summary, ML solutions have been explored and are being developed for several areas, such as
- Vehicle automation,
- Safety applications and driver behavior,
- Planning applications,
- TSMO applications [work zone management, traffic incident management (TIM), road weather management, traffic estimation and prediction for decision support, vulnerable road user detection, intelligent traffic signals, and other miscellaneous operations],
- Asset management,
- Commercial vehicle and freight operations,
- Transit operations, and
- Traveler information and accessibility.
In addition to the application areas listed above, state DOTs are beginning to explore the possibilities of LLMs to support various functions, including their business operations. For example, the Massachusetts DOT, in collaboration with the University of Massachusetts, is training a custom LLM to generate workforce development content based on their contracting documents and design guidelines (Newberry 2024). Agencies deploying ML for these different application areas are starting to report their findings and document the benefits accrued. The Intelligent Transportation Systems (ITS) benefits database developed and maintained by the Intelligent Transportation Systems Joint Program Office (ITS JPO) of the U.S. DOT includes several projects with an ML/AI component. The following two samples are included here to highlight some of the reported benefits and more details can be found through the ITS Deployment Evaluation of the ITS JPO.
- “AI-based Roadway Safety and Work Zone Detection Technology in Nevada Uncovered 20% More Crashes than Previously Reported and Reduced Crash Response Times by Nine to
- Ten Minutes on Average” (ITS Deployment Evaluation 2022a). The Regional Transportation Commission of Southern Nevada, together with the Nevada Highway Patrol and Nevada DOT, launched an AI-based platform in collaboration with a technology company in 2018 that allowed crash locations to be reported in real time. The AI platform reduced emergency response time during traffic crashes by eliminating the time required to dial for help.
- “Video-Based Advanced Analytics is Detailed Enough to Identify Near-Crashes, Classify Road User Types, and Detect Speeding Infractions and Lane Violations” (ITS Deployment Evaluation 2022c). The city of Bellevue, WA used AI algorithms to process traffic camera footage to monitor traffic and road users and potential conflicts. They found that people riding bicycles were 10 times more likely to be involved in a conflict than motorists.
The widespread use of sensors in transportation continues to generate large amounts of data. State DOTs are exploring effective ways to process and extract value from such data. ML tools and methods are anticipated to play an increasingly more important role in supporting DOT operations as ML solutions become more mature over the years. ML may offer effective solutions for processing large data for various applications including system state estimation, prediction/forecasting, condition monitoring, control and optimization, customer relations, and others. These capabilities can fundamentally support all DOT functions (e.g., traffic operations, safety, planning, public transportation, construction, and asset management).
Most ML-related solutions typically start as research ideas/projects or academic studies which are subsequently published in scientific journals and conference proceedings. As part of the literature review for the NCHRP 23-16 project, numerous papers in the Transportation Research Record: Journal of the Transportation Research Board and other journals were reviewed and synthesized. In Chapter 1 of NCHRP Web-Only Document 404: Implementing and Leveraging Machine Learning at State Departments of Transportation, Cetin et al. present a review of the transportation literature on ML methods and the types of application areas these methods have been applied (Cetin et al. 2024). Based on the published literature, applications of ML in traffic operations stand out as one of the most popular areas, with planning and infrastructure/asset management closely trailing behind. Some of the most popular problems to which ML tools have been applied include speed, travel time and traffic flow prediction and estimation, traffic signal optimization, incident detection, vehicle detection, origin-destination demand estimation, dynamic traffic assignment, parking space management, crash severity and frequency analysis, driver behavior analysis, bus arrival estimation, ridesharing, pavement condition assessment, and emissions monitoring. Table 1 summarizes example application areas and specific problems (in no particular order) being addressed with ML methods based on the synthesized literature. This table shows the breadth of applications and different types of problems for which researchers have developed ML solutions. The literature on ML applications in transportation has been continuing to grow rapidly as illustrated in Figure 1 in Chapter 1 of the NCHRP 23-16 conduct of research report (Cetin et al. 2024).
The advanced ML methods published in the literature may eventually be deployed in the field and some have been already implemented by state DOTs. For example, the Louisiana Department of Transportation and Development is moving away from using traditional methods for volume estimation, replacing them with ML-based models. Different agencies have taken different routes based on their specific needs and capabilities. Many DOTs have partnered with universities to explore options for ML implementation. For instance, Iowa DOT partnered with Iowa State University to develop an incident detection system called Traffic Incident Management Enabled by Large-data Innovations. Their system is focused on using already existing surveillance cameras in rural areas where it may take a while for highway patrol to receive notifications. Other agencies have preferred outsourcing these applications, using proprietary software subscription services either as supplements to traditional methods or to replace them. For example, the Nevada and
Table 1. Example types of problems being solved by ML methods for different application areas based on the literature review.
| Application Area | Problems Being Addressed or Solved by ML Methods |
|---|---|
| Operations | Speed, travel time, and traffic flow prediction |
| Traffic signal timing design and optimization | |
| Vehicle classification | |
| Incident detection | |
| Variable speed limit and ramp metering control | |
| Asset management and infrastructure | Pavement crack detection |
| Defect detection for railway tracks | |
| Roadway asset inventory | |
| Preventive maintenance decisions and scheduling | |
| Structural health monitoring | |
| Traffic sign and pavement marking detection | |
| Safety | Crash classification by severity |
| Estimate crash frequency | |
| Classification of driver behavior (e.g., distracted, fatigue) | |
| Planning | Travel mode prediction |
| Estimate origin-destination demand | |
| Dynamic traffic assignment | |
| Estimate car ownership and carpooling behavior | |
| Parking space management | |
| Public transit | Ridership demand prediction |
| Vehicle scheduling and routing decisions | |
| Bus arrival time estimation | |
| Transit signal priority design | |
| Rail maintenance and inspection | |
| Pedestrians and bicycles | Tracking and detecting pedestrians and bicycles |
| Bike sharing demand and usage prediction | |
| Freight | Optimization of freight terminal operations |
| Truck volumes and freight flow estimation | |
| Freight delivery and scheduling | |
| Automated vehicles | Object detection and tracking |
| Motion and route planning | |
| Scene segmentation | |
| Traffic sign and light recognition | |
| Environment | Emission monitoring and estimation |
| Wildlife monitoring (e.g., near highway rights-of-way) | |
| Cybersecurity | Intrusion and anomaly detection |
Florida DOTs have used third-party software for better incident detection and have already seen considerable reductions in secondary crashes (∼%17). Roadway weather management and work zone management are other areas in which many agencies have already implemented new ML-based solutions. As part of the NCHRP 23-16 project, five case studies were conducted with state DOTs to understand their approach to ML solutions. Table 2 shows the list of five DOTs interviewed and the types of applications for which they used ML methods and technologies. The next section presents some guidelines on whether ML solutions would be a viable approach to the problem being considered.
Based on the information presented above, it should be clear that ML methods could be applied to a wide range of problems and challenges DOTs might be facing. State DOTs interested in identifying candidate ML use cases could benefit from the experience of other DOTs. The ITS JPO’s ITS benefits database could be a good resource to search for existing or completed ML deployments. The next section presents some guidelines on whether ML solutions would be a viable approach to the problem being considered.
Table 2. Agencies interviewed for the case studies.
| Agency | Primary Application Area | Needs Addressed | ML Methods | Input Data Sources |
|---|---|---|---|---|
| California Department of Transportation (Caltrans) | Asset management | Litter detection | Deep learning | Video |
| Delaware DOT (DelDOT) | TSMO | Incident detection Traffic flow prediction Proactive traffic management |
Deep learning | Vehicle detectors Video Probe data |
| Iowa DOT | Safety | Highway performance monitoring Incident detection |
Deep learning | Vehicle detectors Video |
| Missouri DOT | TSMO | Incident detection Real-time identification of high crash risk locations Prediction of road conditions including winter weather events |
Deep learning Unsupervised learning Boosting |
Vehicle detectors Video Probe data Incident data |
| Nebraska DOT | Asset Management | Guardrail detection and classification Marked pedestrian crossing detection |
Deep learning | Video |

Decision Gate #1
ML solutions are becoming an integral part of DOT operations and planning, driven by the maturation of ML/AI methodologies. While certain applications, such as license plate recognition from image data, are already mature and have become almost industry standards, others, like traffic signal control using reinforcement learning or incident detection from sensor data, remain in nascent stages. Nevertheless, before proceeding with a decision to consider ML as a potential solution for a given application, one needs to consider whether ML is a viable option or the right approach to the problem. In addition to the commonly used performance metrics (e.g., return on investment, benefit/cost ratio, regulatory compliance) that apply to any other deployments, there are additional criteria that state DOTs might consider in pursuing ML solutions. Assuming the decision-maker has a basic level of familiarity with ML, this initial assessment could be accomplished by considering the following elements:
- Potential reasons for considering ML as a viable solution include the following:
- – ML technology for this problem is already mature (e.g., multiple vendors offer this technology, and multiple DOTs are already deploying it).
- – The nature of the problem aligns well with typical ML applications as it pertains to classification, pattern recognition, image processing, predictive analytics, real-time decision-making, discovering relationships, and so forth.
- – There is a need for automation, improved efficiency/safety, scalable solutions, and extraction of new information or insights from data.
- – The traditional statistical or physics-based approaches are not sufficient in producing satisfactory results.
- – There are sufficient data for model training, validation, and testing.
- – There are established (open-source or otherwise) transferable pre-trained models that are proven to be effective for the problem at hand.
- – The agency has the required resources (e.g., financial, technical knowledge, and computing) needed to support the procurement or development of ML applications.
- Potential reasons for not considering ML for a given problem include the following:
- – The problem is not complex, and there are already established effective traditional solutions.
- – There is no or very limited use of ML for solving this problem, and the agency is not interested in developing new models.
- – Sufficient data or computational resources are not available to train or validate ML models.
- – The solution requires an interpretable model where an explanation is needed as to why a given outcome is generated from the input data.
- – The agency does not have the resources (e.g., financial, technical knowledge, or computing) needed to support the procurement or development of ML applications.
- – The available data are biased or unrepresentative, and using ML models could perpetuate or exacerbate these biases, leading to unfair or unethical outcomes.
- – There are rules and regulations prohibiting the use of ML for the application being considered.
The specific criteria for procuring or deciding to pursue ML solutions will differ significantly between well-established solutions and those still under exploration. For instance, mature methods and pre-trained models might not necessitate additional model training since they are
already calibrated for various field conditions. In contrast, emerging ML models and applications often demand extensive model training. This, in turn, requires large datasets, computational resources, and expertise in ML techniques. Thus, state DOTs must evaluate their capacity to provide the resources needed to develop effective and reliable ML solutions.
To determine if a state DOT should adopt ML solutions, an initial assessment should focus on the maturity of the intended application and any existing implementations or tests by other agencies. Generally, an ML application is considered mature if there are multiple vendors or providers of the desired solution. Such solutions might be offered by transportation consulting companies as well as by those outside the traditional transportation field, such as technology firms or startups. If the application being sought is well-established and mature and no model training is anticipated, the decision to proceed will depend on the commonly used criteria for technology procurement. While the exact criteria might vary from application to application, there are general criteria that many state DOTs consider including benefit-cost ratios, reliability, interoperability, scalability, security, compliance, usability, longevity, environmental considerations, vendor’s reputation and track record, training requirements, support and maintenance, customizability, and contractual terms. In addition to these, the accuracy of the ML solution needs to be evaluated to ensure the agency’s requirements are met. Furthermore, any required computational resources need to be identified.
If the state DOT is considering an ML solution that will require model training and development, there are additional criteria to be considered, including the following:
- Availability of data: Are there enough quality data available for model training and testing? ML models often require labeled data for model development. If sufficient data are not available, a plan for acquiring such data must be made and the resources needed for gathering and processing the data should be identified.
- Trained workforce: Does the agency have sufficient expertise in ML to evaluate, develop, and adopt ML methods? The agency needs to ensure that there is enough expertise and trained personnel to either develop the solution in-house or work with a consultant.
- Institutional policies: Data privacy, resources available for investment in research and model development, the amount of risk the agency is willing to take to achieve its objectives, and bias in ML models are among some of the considerations that need to be addressed.
- State of the practice and technology transfer: Prior experience from other states/agencies implementing ML is an important consideration. If other agencies have developed similar applications and had positive experiences, there might be opportunities for knowledge transfer. Such experiences can help in reducing the model development time and cost.
- Computational resources: Various computational resources are needed for ML applications, including powerful hardware, such as central processing units (CPUs), graphics processing units (GPUs), sufficient RAM, and ample storage, optimized for rapid data processing and storage. High-speed Internet and intranet are essential for data transfers, while cloud services offer scalability for intensive tasks.
- Pilot versus full-scale deployment: The scope of the application can influence the factors to be considered. For example, full-scale deployment requires more in-depth analysis and planning to ensure that a broader range of conditions are addressed effectively by the ML solution. In addition, a larger number of stakeholders might be involved when deploying full-scale solutions. Pilot studies are typically shorter in duration and are meant to test the validity and utility of the ML solution in a constrained environment. Pilot studies involve less risk in case of unsatisfactory model performance whereas the risk of failure is higher with full-scale applications, as the failure may result in significant disruptions or wasted resources. In addition, life cycle and maintenance costs need to be considered with full-scale deployments.
Based on an initial assessment of the considerations and criteria listed above, the agency can decide whether to pursue ML for their given problem. Furthermore, the deployment of ML solutions must carefully navigate through a complex terrain of legal and regulatory frameworks at local, state, and federal levels. These regulations, which govern different aspects of AI/ML, such as data privacy, ethical usage, transparency, and application-specific restrictions, play a critical role in shaping the project’s scope, design, and implementation strategies. The subsequent steps in this guide provide additional information and a more in-depth evaluation of the requirements and other considerations for ML applications in transportation.

Step 2: Assess Gaps
Once it is decided that ML is a desirable approach for the problem at hand, the agency team will want to conduct a more detailed inventory of their available resources and skills to support an ML pilot project. The team must estimate the resources that will be needed to execute the project to identify potential gaps. While traditional transportation projects at state DOTs have many physical infrastructure considerations (e.g., making roadway infrastructure improvements, retiming signals, and deploying proven safety countermeasures), ML projects bring new digital infrastructure considerations, including specific data, storage, and computing considerations. Additionally, ML projects may bring new workforce, funding, and other considerations (e.g., privacy). See Figure 6.
Table 3 summarizes key questions the agency may want to consider before planning its specific pilot project. Essentially, in this step, the agency may want to ask the following:
- What resources do we have to support an ML pilot project?
- What resources do we need to support an ML pilot project?
Data
The team may want to start by defining the data, including identifying what data elements are available and what data elements are needed for the ML application. Just because a data source is available does not mean it will be valuable for the ML application. Often, data transformations are necessary to make certain elements potentially useful for the ML application. But transformations alone may not be sufficient. New data may need to be added to the mix for the ML application to be effective. For example, features like lane and minute-level traffic data feeds would typically not be necessary for legacy traffic management center (TMC) operations. However, as illustrated by DelDOT in their case study, these data become very important as input to ML algorithms for predicting traffic conditions at a higher level of granularity (see Chapter 3 in Cetin et al. 2024).
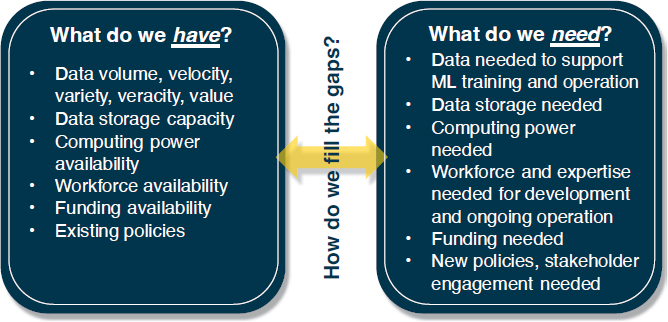
Table 3. Key questions to assess availability and gaps to support ML project.
| Resource Availability | Key Questions to Assess | Key Questions to Assess Gaps |
|---|---|---|
| Data | What sources of data do we have already? For each available data source, what is its volume, velocity, variety, veracity, and value? |
How much data are likely required for the use case? Do we need additional sources of data? How frequently should we collect data to capture time-dependent changes in the system? |
| Storage | How are our data currently stored? How much available storage do we have? |
For the size of data required for the use case, how much storage might we need? |
| Computing | What computing resources do we currently have? | What type and how much computing power might we need for ML model training? For ML model operation? If using cloud computing, which provider, how many resources, and what services should we acquire? Central or edge computing? How frequently do we need to retrain the ML model? |
| Workforce | What data science expertise and experience do we have within our workforce and what is their availability? | Do we need additional expertise in development or deployment, and with whom can we work that has that expertise? |
| Funding | What sources of funding do we have to support our ML pilot? | Are there additional funding sources we should seek out? |
| Other | What existing policies might impact our ML pilot? Are there any concerns regarding collecting and storing data containingpersonally identifiable information (PII) for ML training and/or deployment? What resources do we have to support long-term maintenance once the system is deployed? |
To be compliant with existing policies, do we need to reassess our data collection strategy? Conduct additional stakeholder outreach? Expand policies or security for sensitive data? What resources might we need to sustain the ML application long-term (e.g., funding, staff, software, data inputs, etc.)? |
Modern ML algorithms require training on massive amounts of data to make inferences or predictions. In recent years, artificial NN and deep learning frameworks have surpassed other types of algorithms in complex tasks such as machine vision and object detection. These algorithms require huge amounts of data to sufficiently train the many parameters that comprise these models. That being said, a trend has been to use pre-trained models [e.g., the “you only look once” (YOLO) algorithm for object detection or LLMs for NLP and natural language understanding tasks] to train a more specialized model. This approach may not require a huge amount of additional data, depending on the use case, but it does require specific, representative data.
Data and their requirements are sometimes characterized by the “5 V’s of Big Data.” Table 4 lists these five characteristics that define data and expands on their definition.
The Five V’s provide a useful framework that DOTs can consider when assessing their data capabilities for ML. Notably, the costs and level of effort associated with realizing the benefits of new data sources are not minor. Even in cases where data collection is cheap, cleaning, curating, standardizing, integrating, and implementing collected data can be expensive and challenging (Lane et al. 2021). In the end, more data may not necessarily be more valuable for an ML application.
Table 4. Five “V’s” of data.
| Data Characteristic | Description |
|---|---|
| Volume | Refers to the quantity of generated and stored data. Because of the proliferation of sensors collecting data, data being logged by users of cellular and Internet services, and the rapid increase in Internet of Things (IoT) devices, terabytes and even petabytes of data are being created. |
| Velocity | Refers to the speed at which data is accumulated. Data are being streamed at higher rates by more devices because of improvements in connectivity such as 5G mobile networks and IoT devices. |
| Variety | Refers to the different types and natures of the data. Data can be structured, semi-structured, or unstructured and come in formats as diverse as sensor data, data tables, raw images, text, videos, or audio files. |
| Veracity | Refers to the assumed quality, completeness, consistency, representativeness, and accuracy of data. |
| Value | Refers to the usefulness of the data in the context of solving understood problems and making better decisions. The value of data is context-dependent with respect to the problem being solved using ML applications. |
Volume
Acquiring and managing training data in sufficient volume to train deep learning algorithms is often among the most arduous and expensive aspects of machine learning pipelines. Modern transportation agencies collect troves of high-resolution data from many sources including traffic detectors, images and video from closed-circuit television (CCTV) cameras, weather stations, vehicle probes, crowdsourced traveler information, and more.
Although there is no formula for the volume of data needed to train algorithms for a given task, practitioners can reason using heuristics. In general, the more complex the task and the more complex the model, the more data will be required to result in desired performance (Brownlee 2019). A simple rule of thumb for computer vision tasks that conduct image classification using deep learning is to include 1,000 images per class, although this number can decrease when using pre-trained models (Mitsa 2019). A learning curve, which plots the training dataset size on the x-axis and an evaluation metric on the y-axis, can be used to determine how additional training data are impacting performance. If the result converges, it may be evidence that more data will not result in greater performance using the same model type.
Insights from Nebraska DOT Case Study on Data Volume
(Chapter 3 in Cetin et al. 2024)
Data management often becomes unwieldy when incorporating such large quantities of data. For example, the Nebraska DOT’s team processed 2.5 million images from its 2019 roadway network profiling to classify guardrails and marked pedestrian crossings. The large size of these video logs proved to be a challenge in transferring data to their vendor providing ML services. In the end, the Nebraska DOT team downloaded the large files to a hard drive and shipped the hard drive to the vendor for processing.
Velocity
Agencies are seeing the implementation of more data collection infrastructures that transfer data in near real-time. In contrast to offline analyses, processing data in real-time through an
ML model poses additional challenges, especially when the data volume is high. These very high data velocity sources are often a challenge to manage and incur significant costs. The costs of data transfer can sometimes outstrip the costs of data storage. These costs scale with the volume and frequency with which data are transferred. Extract-transform-load procedures are necessary, as raw data must be aggregated, cleaned, transformed, linked, standardized, and put through other pre-processing procedures to be fruitfully used as input features to ML models. These transformations require computing resources, and these computing resources scale with the volume and velocity of input data.
Variety
Today, data comes in more forms than ever. Structured data are traditional data that are typically organized into tables and can be stored in a relational database. Semi-structured data are data that conform to some known format or protocol but otherwise are not connected, such as JSON files, sensor data, or comma-separated values files. Unstructured data are unorganized and do not conform to typical data organization schemas, such as video, images, emails, or audio files (Gutta 2020).
The wide variety of data sources that agencies are expected to manage presents complications in data fusion. It may not be immediately clear how to incorporate different forms of data into the same ML pipeline. The data may differ in temporal (e.g., minutes versus hours) or spatial resolutions (e.g., zip codes versus Census tracts). In other cases, different data sources might provide redundant or conflicting information.
Insights from Delaware DOT and Missouri DOT Case Studies on Data Variety
(Chapter 3 in Cetin et al. 2024)
To support their Artificial Intelligence Integrated Transportation Management System (AI-ITMS), Delaware DOT linked many different existing and new data sources of various types, including traffic, weather, travel restriction, CCTV, and probe vehicle data. For example, they made enhancements to data collection capabilities such as instrumenting data loggers to track vehicle dynamics to function as probe vehicle data.
In the St. Louis County AI deployment, Missouri DOT found issues with different data sources providing alerts for the same traffic incidents. The system originally did not have a way to recognize these redundant events and filter them, therefore, double counting and presenting them as separate incidents.
Veracity
The quality, integrity, credibility, completeness, consistency, and accuracy of data must never be taken for granted. Agencies should have quality control processes for obtaining and validating high-quality data to build systems with consistent, predictable results (Vasudevan et al. 2022b). Errors may stem from failures of physical infrastructure. Sensors may go offline unexpectedly, be calibrated poorly, or encounter communication or mechanical issues that result in incomplete or altered data. Even if the sensors are all working, they may be distributed unequally across an area where an ML system will be applied, resulting in biased decision-making. Data may be unintentionally omitted, duplicated, incorrect, incomplete, or inaccurate. For example, data fusion and linkage could result in unintended duplicates that, if fed to an ML model during training, could bias the results.
Early on in their deployment, DelDOT was made aware of data quality issues impacting the robustness and accuracy of their ML models. They employed several techniques to mitigate this issue. They decided to train their algorithms on data that may have been missing, corrupted, or otherwise polluted to ensure that they were sufficiently robust to detect and mitigate communication failures.
Another issue is the lack of labeled data to serve as ground truth. Most data created and collected are unlabeled and unstructured data (e.g., audio, image, video, and unstructured text files). Many ML tasks are supervised tasks (i.e., involve matching features to labels). Therefore, before training algorithms, agencies may have to manually or semi-manually label their data. The level of effort needed for data labeling depends on the complexity of the task. For example, if specific objects (e.g., traffic signs or guardrails) are to be identified from a random image by an ML model (e.g., a semantic segmentation model), the specific pixels making up the objects of interest need to be manually labeled with bounding boxes so that the ML can be trained and tested. This could be very labor intensive. On the other hand, some datasets may already contain the label(s). For example, if the agency is planning to build an ML model for predicting travel times (e.g., as a function of historic travel times, and spatiotemporal attributes) and has access to probe vehicle data, such data already contain the label, and the effort required for data labeling will be minimal. Additionally, pre-trained ML models are likely to already know labels for certain classes since they were previously labeled and trained. For example, Figure 7 shows sample output from YOLOv8, a popular object detection algorithm, which has already been trained to recognize certain classes of objects as shown by the bounding boxes and labels in the image.
Value
Arguably the most important characteristic of data, value is highly context-dependent. Just because an organization or vendor has access to data does not make it valuable. The value of data is reliant on it being an input to models that help organizations solve business needs. If the data create models with high accuracy, but those models are unable to positively impact business needs, then the data are not valuable. One such issue might be the timeliness of data. For instance, suppose that an agency is trying to build ML models to help them predict and respond to traffic incidents. They found that their model has 100% accuracy in classifying incidents, however,

Insights from Delaware DOT Case Study on Data Value
(Chapter 3 in Cetin et al. 2024)
Delaware DOT found that their models required higher resolution data than their TMCs typically worked with. Although they had traffic detection sensors and systems already in place, they were not proving to be sufficiently powerful to make valuable predictions for operators. Therefore, DelDOT increased the resolution of their sensors to provide lane-by-lane traffic information, which provided real value to their operations.
it was trained on and requires data up to 1 hour after the incident has taken place. The TMC needs to be made aware of incidents much quicker than this to respond, and therefore the model provides them no value. Another issue may be data lacking labels to serve as ground truth in training an ML model. Unlabeled data may not be useful for many mainstream applications. For example, raw sensor data (e.g., from cameras, LiDAR, or radar) are unlikely to provide much value when training an ML model to classify road users unless it knows which road user types are of interest and where they are in the training data.
Table 5 summarizes considerations for filling data gaps for each of the five “V’s.”
Table 5. Considerations to fill data gaps.
| Considerations to Fill Data Gaps |
|---|
|
Data Storage
In addition to assessing data availability and gaps, the team will need to assess the data storage capacity, type, and cybersecurity considerations needed to support ML training and, potentially, operation.
Data Storage Capacity
Being a data-driven approach, ML requires a non-trivial quantity of training data to learn underlying patterns. This large quantity of data must be stored and readily accessible to train ML models. Increasingly, agencies have access to and are using large data sources, such as images and videos from cameras, raw text from social media feeds or incident reports, audio from dispatches, and so forth. Not only are these data sources much larger than traditional tabular data sources that dominated data analytics in the past, they are also unstructured, meaning they do not follow a neat, predefined schema. Both the size and the nature of these data sources bring important considerations for data storage. For example, video feeds from a few dozen city cameras may easily impact the capacity of existing data servers housed in the TMCs (Vasudevan et al. 2022b). Doing a “back-of-the-envelope” calculation can provide a rough order of magnitude (ROM) estimate of the amount of data storage needed for training a vision-based ML model (see callout box on “Example Hypothetical ROM estimate of Image Data Storage Capacity for ML Training”).
It can be a tricky balance to gather and store a sufficiently large, representative sample of training images for each class while keeping the overall data size in check. Data size not only directly determines the data storage capacity needed to support ML but also determines the type of data storage to consider.
Example Hypothetical ROM Estimate of Image Data Storage Capacity for ML Training
A common rule of thumb is to have 1,000 images per class when training a DL computer vision model. Using the CostarHD OCTIMA 3430HD Series CCTV camera for purposes of this hypothetical example with 3-megapixel image quality, one can calculate an ROM estimate of the quantity of data needed. 3 megapixels equate to 3 million pixels. Each pixel requires 1 byte in memory for each of the three main color channels (i.e., RGB). Based on this calculation, each RGB color image from this CCTV camera is expected to require roughly 9 MB of storage. If the data scientist hopes to train the ML model to classify 10 different classes (e.g., 10 different vehicle types on the highway), using the 1,000-image per class rule of thumb, then 10,000 different images would be needed. At 9 MB each (without compression), these images would likely require roughly 90 GB of storage space. While 90 GB worth of image data could feasibly be stored on a single laptop (albeit it would take up a nontrivial amount of space), any more than that would likely require additional external storage (e.g., separate flash drive, server, or cloud storage). While the camera may generate 90 GB worth of images, it will do some compression (e.g., configurable H.265/H.264/MJPEG codec compression in this example) and internal post-processing (e.g., noise reduction) with some loss in image quality.
Data Storage Type
Many agencies use their existing data sources when possible (e.g., camera, weather, detector, etc.), whether they are using those data sources directly to develop ML in-house or sharing those data with their consultant or vendor teams to develop ML applications. Regardless of the development approach, the training data must be stored somewhere. A few of the main options are summarized as follows, including considerations for ML:
- Local Data Storage: While some of the agency’s existing agency data sources may already be stored locally (e.g., in files on a laptop, external hard drive, or USB flash drive), others may not be stored yet. For example, most agencies do not store video data from CCTV camera feeds, or if they do, they delete them after a certain amount of time (e.g., 24 hours). But to train an ML model on these data, they must be stored. Because of the unstructured format of video data and their large file size, it may be difficult to store them locally in a spreadsheet or traditional relational database [e.g., search query language (SQL)]. Because of potential capacity constraints of local server storage and the costs to purchase and manage additional servers, many agencies turn to cloud storage options to meet their needs.
- Database Storage: If multiple staff/teams from the agency intend to use and query the data frequently beyond just ML training, database storage might be a good option. This database could be hosted locally or in a cloud location. Unstructured data sources, such as videos, may need to be stored in non-relational databases or NoSQL (non-SQL) databases that allow for format flexibility. Common NoSQL databases include key-value databases (e.g., Redis), document stores (e.g., MongoDB), graph databases (e.g., Neo4j), and column-family stores (e.g., Cassandra), with each suited to different data types and use cases. However, if large unstructured data will only be stored and accessed a few times total without the need for complex or real-time queries, cloud storage may be the best option.
- Cloud Data Storage: Cloud storage is well suited for managing large data and can accommodate all sorts of data formats, including unstructured data. Many cloud providers—such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform—offer a variety of data storage options. Cloud storage costs depend on many factors, including the size of the data being stored, the frequency of data access and retrieval, and data transfers. For example,
Insights from Case Studies on Data Storage Type for ML
(Chapter 3 in Cetin et al. 2024)
Delaware DOT decided to use an onsite solution (i.e., 10 local servers) for both data storage and computing in support of their AI-Integrated Transportation Management System, with redundant instances running on production and test servers.
Nebraska DOT relied on local data storage (i.e., a hard drive) to ship large video data files to their vendor for processing.
The interviewee from Caltrans mentioned that data storage costs for many gigabytes or terabytes of image data can be substantial, even if Google Cloud is used instead of dedicated in-house data servers.
The interviewee from Missouri DOT emphasized that additional data come with additional costs, not just for purchasing or collection, but also for processing, storage, and integration.
- transferring data in or out of the cloud, including uploads and downloads, could incur significant data transfer costs. Cloud storage providers tend to be “pay-as-you-go,” which can help in spreading out the costs as opposed to purchasing a new local server with large upfront costs. Often, vendors combine cloud storage with computing services in their cost packages. Examples and a further discussion are provided in this chapter’s section on “Computing.”
Cybersecurity
Each data storage type has cybersecurity considerations. While local storage allows for full customizability of how the data are stored (i.e., in what file or database structure) and what security mechanisms and permissions are used, this customizability generally comes with a higher level of effort to set up and maintain. If the agency lacks sufficient technical expertise to set up and maintain the local data storage, then it could lead to cybersecurity vulnerabilities. Additionally, if local data storage is used, the agency may want to back up the data somehow (e.g., make a copy on another local server) in case of hardware failure. With cloud data storage, some of these risks, such as data backups, are pushed to the storage provider. If cloud data storage is used, and especially if the data contain sensitive information, it is important to ensure the data are encrypted both when stored and when being transferred.
Beyond data storage, machine learning presents new potential cybersecurity vulnerabilities. There exist types of cybersecurity attacks specific to ML models that practitioners must be aware of. These attacks may be classified as security-based attacks or privacy-based attacks. Security-based attacks can cause the ML model to function in unintended ways, such as targeting training data for alteration or forcing models to output desired results. Privacy-based attacks refer to unintentional information leakage regarding data or the machine learning model (Rigaki and Garcia 2023).
Common forms of security-based issues are poisoning attacks and evasion attacks. In a poisoning attack, an adversary “poisons” the training data to alter the performance of the ML model. They do this by injecting data points into the training data to change tuned model parameters. These poison data may be highly noisy and solely degrade system accuracy, or they may be designed specifically to alter system performance in a specified way. For example, an attacker might label stop signs as yield signs, leading to a trained machine vision model that could not recognize stop signs. An evasion attack occurs during the testing of an ML model. The adversary intends to create an incorrect system perception. Following the stop sign example from earlier, some classification systems have been confused by putting reflective stickers on the sign. This would be an example of an evasion attack (Pitropakis et al. 2019).
There exist different types of privacy-based ML cybersecurity attacks that include membership inference, reconstruction, property inference, and model extraction. The most popular category of privacy attacks, membership inference, tries to determine whether a sample of input data was part of the training data. The goal is to retrieve information about the training data. This type of attack may be an issue in settings where potential adversaries have access to the model for querying. Reconstruction attacks attempt to recreate one or more training samples, possibly acquiring sensitive information. Property inference attacks extract properties of the overall dataset that were not explicitly encoded as labels or features. Finally, model extraction attacks attempt to partially or fully reconstruct a model (Rigaki and Garcia 2023).
Practitioners should be aware of ML cybersecurity best practices as they emerge. It is key to understand that when using ML, attackers do not necessarily need to gain access to the stored data to uncover sensitive information. If they have enough access to the model, the previously stated methods could create privacy leaks or lead to other cybersecurity concerns.
As AI services become more available and integrated into more people’s daily lives, there are new cybersecurity considerations to be aware of. For instance, professionals are now using LLM interfaces such as ChatGPT for various purposes like document summarization and brainstorming. However, it should be noted that users’ conversation history with ChatGPT may be collected, as well as information about the user’s account. This data may be used for training further models. Responsible practitioners should consider refraining from sharing sensitive information with ChatGPT and similar AI applications. As AI applications become more dispersed, these concerns may be less prevalent. For instance, if an organization has its own LLM models and applications that are hosted and maintained locally, concerns about data leakage are mitigated.
Computing
Computing is the “muscle” behind ML training and operation. The types and levels of computing resources needed for ML model training may be different from those needed for ML model operation, and both depend on the nature of the use case (e.g., the scale of data and the complexity of the task). Agencies seeking to simply implement a pre-trained ML model may not need intensive computing resources. On the other hand, agencies seeking to train a specialized ML model on large-scale unstructured data may need significant computing power.
Parallel, distributed, and/or clustered computing is often used to train large-scale ML models offline to augment processing power (Vasudevan et al. 2022b). For example, Nebraska DOT’s consultant team used virtual machines with NVIDIA GPUs, which parallelize processing, for convolutional neural network model training using about 1,500 labeled images containing guardrails and guardrail attenuators (see Chapter 3 in Cetin et al. 2024). Once trained, edge computing, which is a distributed computing paradigm with data storage and computation close to the data sources often at or near sensors rather than at the TMC, can help ML models operate in real or near-real-time.
Holding computational resources constant, as data quantity and ML model complexity increase so too do the model training and execution times. For example, as part of NCHRP Research Report 997: Algorithms to Convert Basic Safety Messages into Traffic Measures (Vasudevan et al. 2022a), the research team recorded increases in ML model training and execution times as the market penetration rate of CVs increased (i.e., the quantity of data ingested increased). This project designed algorithms to detect and verify incidents algorithm and the queue length estimation. For details on the training and execution times as well as the server specifications behind the local computing resources used to train and execute the ML models, see Appendix C of Vasudevan et al. (2022a). These ML algorithms used simulated basic safety message (BSM) data, which behave more cleanly than real-world data. The training and execution times assumed no errors or gaps in communication and assumed the BSM data were already packaged and stored in the same location as the ML script, ready to run. These assumptions are unlikely to hold true in a real-world environment in which data can be messy and must be transmitted to different locations. To operate in real or near-real-time, ML applications are likely to require expanded computing resources.
Legacy systems used by many state and local transportation agencies often have insufficient data storage and computational power for ML applications (Vasudevan et al. 2022b). Researchers supporting the Iowa DOT pointed to the requirement of high-performance computing as a challenge to potential large-scale, statewide deployment of ML applications, based on information provided in their case study (see Chapter 3 in Cetin et al. 2024). They also mentioned that large-scale deployment would require increased bandwidth to support real-time access to large amounts of data from sensors and cameras. In another example, because their existing data storage and computing power were insufficient, DelDOT purchased 10 servers to handle storage and computing to support their AI-ITMS, based on information provided in their case study (see Chapter 3 in Cetin et al. 2024).
Cloud computing is another possible solution that has become increasingly popular as large tech companies expand their offerings, including integrated storage and computing services. Types of clouds include public (e.g., AWS, Microsoft Azure, Google Cloud Platform), private (e.g., IBM Private Cloud, VMware vSphere), and hybrid clouds (e.g., OpenStack). Popular cloud service models that can apply across cloud types include Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). These service models generally come with an initial set-up cost and then monthly costs depending on the scale of the data, features used, and level of access desired.
According to lessons learned from a case study on “Leveraging Existing Infrastructure and Computer Vision for Pedestrian Detection” in New York City (ITS Deployment Evaluation 2022b), cloud-based server and storage service is cheaper than using a local server in the short-term (i.e., less than 5 years). However, a local server could be a good option for testing or piloting an ML system since it is easy to set up. The cost to implement local server-based video data storage and networking services to support 68 traffic cameras in New York City was estimated at $1,663 per year (ITS Deployment Evaluation 2021). Similar cloud-based storage and computing services were estimated at between approximately $515 and $1,027 per year depending on how frequently the data are accessed based on Amazon’s public cloud service, AWS, using an Elastic Compute Cloud instance with 2 CPUs and 1 GB of memory, and Simple Storage Service (Ozbay et al. 2021).
Additional insights concerning computing are documented in the report on Artificial Intelligence (AI) for Intelligent Transportation Systems (ITS): Challenges and Potential Solutions, Insights, and Lessons Learned (Vasudevan et al. 2022b). With a large amount of data being collected, transmitted, and processed to support ML, issues related to bandwidth and latency may still arise with cloud computing. Edge computing, which brings computing as close to the source of the data as possible to reduce latency and bandwidth use, could be a solution, especially for real-time and near-real-time ML applications. More than half of the respondents to a 2021 Sources Sought Notice on AI for ITS mentioned making use of edge computing in their AI-enabled applications, as noted in Appendix A of Vasudevan et al. (2022b).
Overall, as AI/ML solutions typically require significant computational resources and efficient communication networks to function properly, the interviewee from Caltrans suggested effective coordination with the agency’s information technology (IT) department (see Chapter 3 in Cetin et al. 2024). Researchers for NCHRP Research Report 997 (Vasudevan et al. 2022b) made a similar recommendation to agency practitioners to assess the availability and maturity of their IT infrastructure and skillset to support big data processes (specifically for algorithms that use ML methods). While there is an upfront cost to upgrade digital infrastructure and likely monthly costs if using data storage and/or computing services, the benefit of doing so can be felt beyond ML applications at agencies.
Table 6 summarizes considerations for filling data storage and computing gaps.
Workforce and Organizational Considerations
A lack of workforce talent, education, and training is often cited as a major gap in the deployment and integration of AI systems into the operations of government agencies. ITS systems are usually operated and managed by engineers with civil engineering backgrounds, with degree programs that may have not started teaching AI concepts (Vasudevan et al. 2022b).
This often means AI/ML work done at state DOTs is done through contractors. In fact, much of state DOT work is outsourced. For example, one state DOT mentioned during a panel session at the American Society of Civil Engineers International Conference on Transportation and Development 2022 that it outsources 93–94% of its design work and over 60% of its
Table 6. Considerations for filling data storage and computing gaps to support ML.
| Considerations to Fill Data Storage and Computing Gaps |
|---|
|
construction and engineering work overall. Given that the general trend for state DOTs is to contract out a significant portion of work, the role of agency staff supporting ML projects is (usually) not as developers or programmers of ML applications, but rather as technical managers who need to understand strengths, weaknesses, and risks and to recognize unrealistic vendor claims (Vasudevan et al. 2022b).
The Institute for Operations Research and the Management Sciences (INFORMS) (INFORMS Organization Support Resources Subcommittee 2019) uses the terminology “readiness for analytics” to measure the success an organization will find when implementing analytics (including ML) projects, or what needs to change to improve odds of success. Among the indicators for success are belief and commitment from leadership that analytics add value to business
Insights from Case Studies on Workforce Considerations
(Chapter 3 in Cetin et al. 2024)
The Missouri DOT project team was a champion of the project even though its members did not consider themselves experts in AI/ML. They were able to get their leadership onboard with supporting the project by emphasizing the efficiencies and improved operational capacity that AI/ML could achieve. They won over operators by setting realistic expectations of system performance and emphasizing that the systems are not magic and would have to be improved and tuned over time but would nonetheless result in better outcomes.
It is not just developers and project managers that should have familiarity and training with AI concepts. The Delaware DOT team understood that it was imperative that all operations staff understood the changes and advantages that their AI-ITMS program would entail. They involved technicians like TMC operators and maintenance staff. Street-level maintenance personnel were trained to understand the necessity of having a stable, reliable data pipeline for ingest into ML systems. Coordination with vendors and state IT systems was another key focus of Delaware DOT.
processes, that employees embrace analytics as a tool to help them better do their jobs, and that the organization has a documented process for making structured decisions. Building a data-literate, data-driven organization requires buy-in from the top to the bottom of the agency.
Some agencies may choose to invest in internal technical capabilities instead of relying fully on outsourcing. DelDOT has its own internal software development team that partners with consultants to develop and manage all its ML applications. This helps it build systems designed for scalability, resilience, and iterability. The DOT can more promptly and cost-effectively fulfill change requests by not relying fully on vendors.
Table 7 summarizes considerations for filling workforce and organizational gaps.
Funding
All the previous digital infrastructure considerations—data, storage, and computing—could bring new costs for the agency depending on their existing state to support new ML pilots. Additionally, the need for an ML-trained workforce, which is already in high demand across sectors, could also prove challenging for state and local agencies with limited resources. Agencies are responsible for spending public funding responsibly and, therefore, tend to avoid investing in innovative solutions that have not been tried before (Vasudevan et al. 2022b). Larger state DOTs generally have more tolerance for downside investment risk with the potential for substantial at-scale benefits if successful (Gettman 2019).
Market research on AI for ITS (Appendix A in Vasudevan et al. 2022b) revealed that budget constraints and limited federal grant availability, particularly “short-term” funding to kickstart new projects, are the biggest barriers to widespread ML implementation. Several state and local agencies have used federal Advanced Transportation and Congestion Management Technologies Deployment (ATCMTD) grant funding to kickstart their AI/ML deployments, including but not limited to Delaware DOT, Tennessee DOT, Washington State DOT, Missouri DOT, and the City of Detroit. For example, DelDOT used its nearly $5 million in ATCMTD funding to design, develop, and deploy its AI-ITMS (see Chapter 3 in Cetin et al. 2024). Missouri DOT funded its $2 million project over four years—which includes predictive analytics, advanced video analytics, and weather analytics—as a 50/50 split between the grant funding ($1 million from ATCMTD) and self-funding, with the former going toward deployment of predictive analytics and the latter toward the other two technologies, as described in their case study (see Chapter 3 in Cetin et al. 2024). In other cases, vendors have offered reduced rates to agencies to pilot their technologies.
Results from a survey of state and local agencies in support of this research effort showed that two-thirds of the respondents (10 of 15 respondents) estimated the annual operating cost
Table 7. Considerations to fill workforce gaps.
| Considerations to Fill Workforce Gaps |
|---|
|
for their ML application at less than or equal to $50,000 while three respondents reported the annual operating cost to exceed $300,000 (see Chapter 2 in Cetin et al. 2024). However, these are the estimated operating costs of the deployed ML application, not the ML pilot project costs, as reported by the survey respondents. “Lack of dedicated funding” was the third most commonly reported challenge by survey respondents in the development and adoption of ML applications, behind “lack of AI/ML skilled workforce” and “integrating ML with existing processes and systems.”
Table 8 summarizes potential considerations for filling funding gaps.
Other Considerations
In addition to inventorying physical infrastructure, digital infrastructure, workforce availability, and funding availability, lessons learned from agencies deploying ML have pointed to a need to assess institutional practices and policies for potential gaps. These institutional considerations may include those related to privacy, ethics and equity, liability, and so on. For an in-depth discussion and examples of privacy, ethics and equity, liability, and other important considerations with respect to AI in transportation, please see the 2022 report titled Artificial Intelligence (AI) for Intelligent Transportation Systems (ITS): Challenges and Potential Solutions, Insights, and Lessons Learned (Vasudevan et al. 2022b).
Collecting and storing data could conflict with existing privacy policies. For example, to be compliant with their computer vision application, the City of Detroit follows the city’s ordinance on how cameras can be used, including how long video recordings can be stored (Vasudevan et al. 2022b). Often data from existing agency feeds (e.g., CCTV) are not stored or, if they are stored, they are only stored for a short period (e.g., 24 hours) before they are automatically deleted. Storing these data for ML applications could bring new privacy concerns, especially if they contain Personally Identifiable Information (PII). For example, Missouri DOT disposes of processed images and videos immediately after they are used in its advanced video analytics algorithm to protect privacy, as mentioned in its case study (see Chapter 3 in Cetin et al. 2024). “Safeguarding the privacy and security of sensitive data” was only reported by three survey respondents as a challenge their agencies foresee in the development and adoption of future ML applications (see Chapter 2 in Cetin et al. 2024). However, it can be difficult to foresee all potential privacy and security concerns before planning and executing an ML project. Notably, workforce, system integration, and funding concerns appeared to be more pressing for survey respondents.
Another consideration that should not be overlooked is the long-term maintenance of the ML application. It is easy to get caught up in the excitement of a new ML pilot deployment and focus on how to get it up and running. However, it is important to consider aspects relevant across the ML application lifecycle, particularly those that span beyond the pilot period, from the very beginning. These lifecycle aspects may include lifecycle costs and securing ongoing
Table 8. Considerations to fill funding gaps.
| Considerations to Fill Funding Gaps |
|---|
|
funding for operations and maintenance, staff oversight, software updates, and new data. Often, emerging technology pilots may be supported by short-term technology-focused grants. The agency may want to assess the availability of potential resources to support long-term operations and maintenance once the system is fully deployed and grant funding runs out. Additionally, vendor and/or consultant technical support may not continue past the ML development and setup phase. The agency may need to identify one or more of its staff to be responsible for monitoring the application over the long term, including data changes and software updates. See Step 8: Operations & Maintenance for more information.
Table 9 summarizes potential considerations for filling other common gaps, such as privacy and other policy gaps.
Any gaps identified—including those concerning data, storage, computing, workforce, funding, and policy as discussed in this section—will directly inform how the team may want to plan their ML pilot project in Decision Gate #2. Since it is difficult to predict all possible resources needed to successfully execute a new ML project at its onset, a hybrid project management approach following an agile development methodology for Steps 2 through 5 could help provide the team with the flexibility to iterate and grow. This iterative approach will be discussed further in Step 5.
Table 9. Considerations to fill other common gaps.
| Considerations to Fill Other Common Gaps |
|---|
|

Step 3: Build Business Case
More than ever, regional, state, and local transportation planning organizations and other agencies around the nation are being asked to provide concrete, quantitative justifications for their programs and related expenses. Advanced information technologies applied to transportation systems, such as ML, have to compete with traditional infrastructure projects by demonstrating their value-add (FHWA Office of Operations 2020). The document or briefing demonstrating the value of a project is typically called the business case. Building the business case includes defining the opportunity, conducting a benefit-cost analysis (BCA), and communicating with various stakeholder groups, especially leadership, to gain support for the pilot project.
Defining the Opportunity
The first step in building out the business case for an ML deployment is to describe the business opportunity in broad terms. This should have already been conducted in Step 1, where candidate transportation use cases were considered. This can answer the question of why the new process or system is being considered for development and what needs it is addressing (DIU 2022a).
The project team must identify relevant stakeholders and bring them into the discussion to adequately understand the opportunities for process improvement presented by ML. These stakeholders may include agency leadership, operators, programmers, IT departments, end-users of the system, and segments of the general public. It is especially important to define who the types of end-users will be and who could experience downstream effects, positive or negative, from the system being implemented (DIU 2022a).
The project team should collaborate with stakeholders to refine the problem statement, making it more precise and clearly suited to the ML methods that will be employed. A rigorous understanding of the current state of the process should be gleaned through information collection. Constraints on the project should be factored in, which might be analytical, financial, or political (INFORMS, n.d.). After this exercise has occurred, the team will be ready to put together a business case estimating the economic outcomes of the project.
Benefit-Cost Analysis
BCA is a systematic method to quantify and compare expected benefits and costs of potential project deployments. The goal of a BCA is to give an objective methodology to estimate the outcomes of investment in a project and to quantify their value. It allows the project team to compare the anticipated benefits of a project over a specified period and compare them to anticipated project costs. BCA can also be used to compare the potential efficacies of alternative projects competing for resources. It is imperative that teams capture the baseline state of the system in terms of benefits and costs so that projected outcomes can be compared to the “no-build” system state.
Benefits
The first step of a BCA is to identify all potential benefits of a project. Some benefits may be difficult to capture or contain high levels of uncertainty (Office of the Secretary 2022). This is
especially true in the case of emerging technology, such as ML applications, applied in a field with few prior deployments, such as transportation. Nonetheless, attempting to identify and quantify benefits is crucial to advocating for a potential project.
One of the most reliable ways to identify and estimate project benefits is to research similar projects that have already been implemented and investigate their resulting benefits. The ITS Deployment Evaluation website, hosted by the U.S. DOT ITS JPO, collects and summarizes evaluation reports of technology deployments in transportation. It may be a good starting place to search for similar projects and learn what benefits were realized for teams in the early stages of the BCA for their ML project.
As ML in transportation systems is still quite immature, prospective deployers will likely have few precedents on which they can base their benefit estimations. The following sections describe benefits typically associated with ML and analytics projects. Following that are benefits typically associated with transportation projects. Practitioners should do their best to merge the two given the expected outcomes and improvement goals of their project.
Machine Learning-Related Benefits
Benefits associated with ML, and analytics projects more broadly, can be separated into soft and hard value generation. Projects may generate a multitude of both types of value. Soft value usually has to do with improvements in customer satisfaction or the “experiences” of users, which can be difficult to quantify. Hard value is more directly measurable and generally easier to explain. Figure 8 shows example types of ML value and enumerates the different types of value typically generated by ML projects, as well as examples in transportation (INFORMS Organization Support Resources Subcommittee 2019).
Transportation-Related Benefits
Professionals at transportation agencies will be more familiar with the typical benefits of transportation projects and ITS deployments. As the goal of an ML implementation by an agency is ultimately to result in these benefits, it is imperative to link the ML benefits to the transportation
system benefits. Typical categories of benefits of transportation projects include, but are not limited to, safety benefits (e.g., crash and fatality reductions), mobility benefits (e.g., travel time savings), efficiency/productivity benefits (e.g., operating cost savings), and environmental benefits (e.g., emissions reductions and public health benefits) (Office of the Secretary 2022). There exists a large trove of literature on methods for converting these benefits into dollar figures. The Federal Highway Administration (FHWA) Office of Operations Benefit/Cost Analysis Desk Reference may be of use in this task (FHWA Office of Operations 2020).
Costs
Costs included in a BCA should include the resources expected to go into project development and the costs of maintaining the new system over time (Office of the Secretary 2022). Costs should account for all the economic resources (including capital, land, labor, and materials) that are expended on the project throughout the project life cycle. These include not just upfront capital expenditures and development costs, but also ongoing operations and maintenance costs that will be incurred across the lifespan of the new system, process, or technology. For a typical ML implementation, these may include costs for consultants, hiring developers, proprietary software, additional data collection capabilities like sensors, storing and sharing data, computation for training and deploying models, and monitoring and maintaining models after they are deployed. The gaps determined in Step 2 may be useful in estimating costs, as these likely will be the areas that will require investment in equipment, training, and labor.
BCA Measures
Typically, the BCA will result in an all-encompassing measure that denotes the overall value (in monetary terms) of the proposed project. This metric aggregates the spectrum of costs and benefits while applying economic principles to distill the larger analysis into one or a few numbers. Best practices to follow when calculating this metric include adjustments for inflation, discounting future revenues/costs according to the time value of money, defining the relevant period of analysis, and defining the scope of analysis (Office of the Secretary 2022).
Although there are many BCA metrics that serve different purposes, three of the most popular include net present value (NPV), benefit-cost ratio (BCR), and return on investment (ROI). The differences between the three are noted as follows:
- NPV: Discounts all benefits and costs over the project’s life cycle to the present, then subtracts the costs from the benefits. If the benefits outweigh the costs, then the NPV is positive, and the project may be considered economically efficient (Office of the Secretary 2022).
- BCR: Often used in project evaluations when evaluating competing proposals. The present value of benefits is put in the numerator while the present value of costs is put in the denominator. The ratio is commonly shown as a quotient (e.g., 2.0). If the BCR is above 1.0, the project may be considered economically efficient (Office of the Secretary 2022).
- ROI: Expresses the project’s “profitability” as a simple percentage. ROI is calculated by dividing a numerator of discounted net benefits minus discounted net costs, dividing by the discounted net costs, and multiplying by 100. It is a very intuitive gauge for the efficiency of expenses and is often used to communicate with decision-makers. An ROI greater than 0% may be considered economically efficient.
Communicating the Business Case
After the problem has been properly framed and a BCA conducted, the project team has an opportunity to demonstrate the value of their potential ML project to stakeholders. The team should tailor the presentation of the results to the audience they wish to persuade, making sure that the information is accessible, relevant, and relatable (ITS Joint Program Office n.d.).
Decision-makers, operators, and the general public may find different aspects of the BCA more appealing than others. Generally, the audience wants to understand how the benefits help to improve their lives and that the funds they provide are being spent efficiently. The following are considerations for these three audiences (ITS Joint Program Office n.d.):
- Decision-makers: Decision-makers are the agency officials who must sign off on projects and who will determine which projects are funded. They must compare the efficiency of a wide variety of potential and existing projects and determine how they align with agency priorities. Measures such as BCR or ROI may be most compelling to this group because they allow for comparability across disparate projects and easily distill complex information. They typically want to practice fiscal responsibility, which can be shown through these metrics.
- Operators: Operators are interested in optimizing the processes of their day-to-day jobs without having to make dramatic changes to the way they are accustomed to operating. Typically, they are interested in efficiencies that would improve their work experience and improve key performance indicators that measure the efficacy of their work. Consider presenting them with specific anticipated benefits that fall under these categories.
- General public: Obtaining the buy-in of the public is often key to deployment success. This may be especially true in the case of ML projects where the public may have preconceived notions and skepticism of this technology. Consider sharing benefits related to the performance of transportation system outcomes, such as decreased travel times or reduced crash risk.

Decision Gate #2
After deciding that an ML solution is a good fit for an agency’s transportation use case, the agency then must decide whether and how to move ahead with an ML pilot. To do this, they can implement a systematic process to inventory the goals, resources, conditions, and constraints that the organization faces.
Before embarking on a pilot, the agency will want a clear idea of the barriers and obstacles that will have to be overcome, what level of effort and funding addressing these obstacles might require, what outcomes and benefits the project is expected to realize, and ultimately, whether the project makes sense economically and in terms of addressing transportation priorities of the agency. Team members will have to communicate the costs, challenges, and benefits expected during the pilot implementation to stakeholders, including agency leadership. By conducting a thorough gap analysis and compiling a business case, they can give a reasonable, structured, evidence-based estimate of the project outcomes to stakeholders. Then, using that analysis, key decision-makers in the agency can decide whether moving ahead with pilot implementation is a beneficial decision or not and, if yes, then how to plan the pilot. Key questions to interrogate when deciding to move ahead with an ML pilot include the following:
-
Data
- – Will the ML application require significant amounts of new data for training?
- – If it does require data, do we believe we have access to data of sufficient volume, velocity, variety, veracity, and value to train an acceptable algorithm?
- – If not, what would the expected costs and effort of data acquisition be?
-
Storage
- – Do we have sufficient storage infrastructure to house the data needed to power and evaluate our ML application?
- – If no, what type of storage system might be preferable? What would be the expected cost of storage acquisition and transfer of data in and out of storage?
-
Computing
- – Do we, or our consultants, have sufficient computing infrastructure for training and/or using the ML application in operations?
- – If no, what would be the cost of acquiring or renting sufficient compute infrastructure?
-
Workforce
- – Do we have the workforce available for this project with sufficient skills and availability to advise on the implementation of the ML system? Is our workforce knowledgeable enough about ML to work with the proposed system?
- – If not, would we consider providing training to current staff, hiring new staff, or contracting consultants?
-
Funding
- – What sources of funding do we expect to have for our ML pilot?
- – What is the fair price for an ML project?
- – Will those sources likely be sufficient to produce a minimum viable product?
Table 10. Potential benefits and risks of different ML development pathways.
| Purchasing an “Out-of-the-Box” ML Solution | Developing a Custom ML Solution | |
|---|---|---|
| Benefits |
|
|
| Risks |
|
|
-
Business Case
- – What business case metric (NPV, BCR, ROI) is most relevant to our project’s viability?
- – Does the estimate for this metric meet a sufficient threshold to be considered economically viable?
- – Do the expected benefits incurred align with the division’s priorities?
- – Have we communicated the business case to key stakeholders and gained their buy-in for the ML pilot?
Based on the answers to these key questions, the project team can gauge whether or not moving forward with a pilot is desirable, whether it should be postponed until conditions are more favorable, or whether it should be canceled altogether. If moving forward, the project team may start deciding among high-level approaches or pathways to pilot execution. Two possible ML development pathways, their potential benefits, and risks are summarized in Table 10.
If the agency decides to pursue developing a custom ML solution, this custom solution could be developed using the agency’s in-house expertise or by hiring outside expertise. The potential benefits and risks of these two approaches are summarized in Table 11.
Table 11. Potential benefits and risks of different staffing approaches.
| Using In-House Developers | Hiring External Developers (e.g., Consultants) | |
|---|---|---|
| Benefits |
|
|
| Risks |
|
|
Table 12. Potential benefits and risks of local versus cloud storage/computing.
| Purchasing/Using On-Premise Servers | Purchasing/Using Cloud Services | |
|---|---|---|
| Benefits |
|
|
| Risks |
|
|
In addition to deciding whether to develop a custom ML solution and hire external developers, the agency will need to decide whether to use or purchase on-premise hardware or purchase cloud services for data storage and computing needs associated with the ML application. The potential benefits and risks of these two options are summarized in Table 12.
The following sections outline the process that agencies may want to take to successfully plan and execute their ML pilot.

Step 4: Plan Pilot
Among survey responses from state DOT staff, most ML applications were characterized as being in the “research and development stage” and have been used in practice for less than 1 year (see Chapter 2 in Cetin et al. 2024). This suggests that ML projects at state DOTs are likely fit for pilot projects, as opposed to wide rollouts. Since a new pilot project on ML is likely to have greater uncertainty than a traditional deployment project of a more familiar technology, it may be helpful to take an agile or hybrid approach to planning and project management.
Many tools (e.g., worksheets, frameworks, sample models) exist to guide the planning process for analytics/AI/ML projects. The specific planning approach best suited to a given agency will depend on a variety of contextual factors (e.g., planning requirements for the given funding mechanism, level of uncertainty, and familiarity with the technology). Regardless of the planning approach and/or tools used, there are a few key elements worth considering when planning an ML pilot project in transportation.
Phases for Structuring Analytics Projects, Including ML
(INFORMS Organization Support Resources Subcommittee 2019)
According to the Institute for Operations Research and the Management Science (INFORMS), there are typically four basic phases for structuring analytics projects:
- Problem definition or business need identification (see Step 2 of this Guide)
- Agreement on requirements, scope, assumptions, project value, champions, and partnerships, including drafting a project charter (see Step 4 of this Guide)
- Prototyping and development, including defining the modeling approach, technology design architecture, and metrics of success (see Step 5 of this Guide)
- Implementation and sustainment plan (see Steps 6 through 8 of this Guide)
Establishing a project charter and securing agreement from project stakeholders on core aspects of the proposed ML pilot project (e.g., preliminary scope, schedule, cost, assumptions, staff resources) are considered best practices. However, drafting detailed systems engineering documents (e.g., concept of operations) may not be worthwhile when planning for an ML pilot project since there are many uncertainties when trying out and integrating a new technology into the transportation system. While these elements (i.e., design/architecture, evaluation, data management, procurement, etc.) are certainly important, it may benefit the agency team to consider them incrementally and dynamically, with regular stakeholder input.
ML Pilot Initial Planning
An ML pilot project at an agency might differ from typical deployment projects in its scope and the agency’s familiarity with the technology. Therefore, conducting stakeholder engagement
and ML pilot planning across shorter time horizons with an agile approach could prove beneficial. For example, an agency team from the Washington State DOT emphasized the importance of regularly engaging with the user community in a highly agile and participatory process when developing ML as part of their ATCMTD deployment (Vasudevan 2022b). However, taking a more flexible approach to planning does not mean avoiding planning altogether. The Nebraska DOT interviewee for the case study emphasized the importance of careful planning and a measured approach when implementing ML technology (see Chapter 3 in Cetin et al. 2024).
Initial planning for an ML pilot project can feel daunting. Defining the project scope can be especially challenging. However, resources exist that could be applied to the transportation context. The Defense Innovation Unit’s (DIU) AI Portfolio includes Responsible AI Guidelines and supporting worksheets for responsible AI/ML project planning, development, and deployment (DIU n.d.). While originating from the Department of Defense, these worksheets are focused on responsible AI and could be applied to transportation as well. The DIU responsible AI planning worksheet (DIU 2022a) provides helpful guidelines and important questions for consideration when planning an ML project. The key elements in the planning worksheet are summarized below, with some modifications to make them more specific to transportation agencies. The following tables apply a generic agency ML pilot project for roadway asset inventorying at a hypothetical, mid-sized state DOT to the DIU responsible AI planning worksheet (DIU 2022a) as an illustrative example.
#1 - Problem Statement and Value Added
It is helpful to provide background information on the current situation and what value the ML solution is expected to provide. This background includes why the system is being developed, what actions or interventions it will inform or support, who will use it, and what will be achieved with it. See the previous step in this roadmap, Step 3: Build Business Case, for additional insights.
| Planning Question #1 | Hypothetical ML Pilot in Transportation Example |
|---|---|
Describe the need for the work and the value that is expected to be provided by the solution.
|
It takes four full-time agency staff an average of 200 hours each (i.e., five full work weeks each) to collect, process, and inventory roadway asset data across the state once each year. The staff consider this a tedious process and one that limits their ability to address other, more critical matters, such as coordinating bridge repairs. Once trained, applying ML for data processing and roadway asset classification has the potential to reduce staff hours spent on this task by half, even while factoring in necessary staff time for manual data validation. Additionally, if the agency decides to procure both new sensors for data collection (e.g., dashcams to mount on fleet vehicles) and ML services from a vendor, then the data quality (e.g., higher resolution), granularity (e.g., continuous video rather than select images), and breadth (e.g., equipping 20% of fleet vehicles as opposed to having a few surveyors take photos) could be improved. These efficiency improvements may also allow for the ability to inventory roadway assets more often than just once per year. |
#2 - ML Tasks and Performance Metrics Compared to Baselines
An ML model is just one aspect of a larger system. Clearly defining the task(s) for the ML model(s) upfront is very helpful for setting and managing stakeholder expectations. It is also critical for guiding technical decisions and avoiding scope creep during project execution. An example of a poorly defined task would be, “improve asset management using machine learning.” A well-defined task includes the purpose, the primary end users, the inputs, the output, ML metrics
(e.g., false positive rate), and operational metrics (e.g., reduced staff level of effort) for evaluation. In many cases, if a suitable quantifiable metric cannot be determined, then ML likely is not a preferable approach. Finally, it is important to establish baselines against which to compare ML performance. A baseline allows the agency to assess whether the system with ML is worse, equal to, or better than the status quo (i.e., the system without ML). See Step 6: Communicate Results in this guide for additional insights on metrics.
| Planning Question #2 | Hypothetical ML Pilot in Transportation Example |
|---|---|
Have you clearly defined tasks, quantitative performance metrics, and a baseline against which to evaluate system performance?
|
The computer vision ML pilot system will be trained to identify and classify regulatory signs—stop, yield, speed limit, one-way, and do not enter signs—in collected roadway asset image data from one district. The locations where the images were taken were tagged with latitude and longitude using GPS. It will also “flag” images in which it suspects one or more regulatory signs are damaged or obstructed. For training and testing, the ML model will use last year’s roadway asset inventory data and labels from staff identifications, counts, and flags (some staff data labeling and cleaning may be required). At a minimum, the ML model is expected to be able to correctly classify 95% of stop signs, 90% of one-way and do not enter signs, 85% of yield signs, and 80% of speed limit signs, with no more than 2% of total signs missed. These thresholds were determined based on discussions with stakeholders who suggested higher thresholds for the most safety-critical signs. Further, the ML model is expected to be able to flag images with a minimum of a 90% F1-Score, with no more than a 3% false negative rate. Currently, it is estimated that roughly 6% of damaged or obstructed signs are missed in this inventory process (baseline). |
#3 - Data and Model Ownership
It is important that ownership of, and responsibility for, all data, all components of the data pipeline, and the trained models are clearly specified and understood by all parties involved to avoid potential surprises or “vendor lock-in” down the road. Additionally, access to the data and data pipeline are critical before, during, and after the project, since these drive ML model functionality. If the data and processing pipeline are inaccessible because of propriety data formats or protocols, then vendor lock-in is likely to occur. It is also important to know (or at least know where to find) information on data provenance, including where the data came from and how they were transformed or processed. Understanding data provenance can help in troubleshooting and assessing data relevance for the ML task.
| Planning Question #3 | Hypothetical ML Pilot in Transportation Example |
|---|---|
Have you evaluated ownership of, access to, provenance of, and relevance of candidate data and models?
|
All data will be collected and owned by the DOT, with select asset inventory data shared with the ML vendor for model training and testing. The vendor is expected to delete all copies of the data no later than 6 months following the conclusion of the model training process unless otherwise stated by the DOT PM. While the ML vendor will own and be responsible for the ML model during the training process, those ownership rights and the final trained model will be transferred to the DOT following the conclusion of the contract (as if it is a deliverable). Additionally, the ML vendor is expected to provide detailed documentation regarding how the model was trained and tested (while still protecting proprietary vendor information), which data were used (including a description of any additional data included outside the purview of the DOT), and instructions on how the model should and should not be applied. |
#4 - Stakeholders
As with any project, it is important to understand all stakeholders involved or affected. This rings especially true for a project involving a new technology, such as ML. The end-user experience is critical, perhaps even more important than algorithm performance. It is considered a best practice to consult users throughout the planning phase to ensure the ML task matches their needs and could provide value beyond simpler methods. When asked who the main users of ML applications are at transportation agencies, a plurality of survey respondents selected “those within my agency/in-house” (37%) (see Chapter 2 in Cetin et al. 2024). Further, in contexts where ML systems will ingest new data and make predictions about people, it is advisable to ensure that those people are aware and comfortable with its intended use. Similarly, if an agency plans on collecting or using data about people for training ML algorithms, it is advisable to provide notice and ask for consent. Finally, humans are expected to bear responsibility for the outcomes of ML. It can be helpful to designate a person responsible for the outcomes of an ML system, especially if those decisions could directly impact a person’s health or well-being.
| Planning Question #4 | Hypothetical ML Pilot in Transportation Example |
|---|---|
Are end users, stakeholders, and the responsible mission owner identified?
|
The end users for the ML model will be the agency’s asset management staff and surveyors responsible for sign inventorying. While the ML model will not make predictions about people directly, its classifications could unintentionally affect populations differently. For example, if the ML model is more likely to misclassify regulatory signs in a particular neighborhood because of the lighting conditions and foliage there, this could lead to adverse effects for the people living there if obstructed or damaged signs in their neighborhood are consistently overlooked. As is currently the case and will remain the case for the ML implementation, responsibility rests on the agency’s asset management lead for any incorrect sign classifications and damaged or obstructed signs that are missed in the inventory process. |
#5 - ML Risk Assessment
While it is always helpful to create a risk log and risk management plan before diving into a new project, there could be additional considerations worth assessing for an ML project. It is important to ask how the ML system could potentially lead to human harm as well as to assess the likelihood and magnitude of potential harm. Potential harm could include physical
| Planning Question #5 | Hypothetical ML Pilot in Transportation Example |
|---|---|
Have you conducted harms modeling to assess the likelihood and magnitude of harm?
|
Automation bias could be a potential risk for the ML application that classifies regulatory signs. Asset management staff could come to over-rely on the ML outputs and fail to notice potential concerns (e.g., signs missed in a certain neighborhood). An ML-driven asset inventorying system that performs poorly could impact not only the end users (i.e., asset management, maintenance, and survey personnel) but also other agency staff that use those classifications for their purposes (e.g., planning, and logistics). Further, as mentioned in the previous planning question, it could potentially impact stakeholders downstream of the ML outputs, such as residents in a neighborhood whose signs are more often missed by the ML model. If damaged or obstructed stop signs are disproportionately missed in that neighborhood by the ML classifier, this could lead to asset management staff failing to fix those signs, which could lead to major safety implications for pedestrians crossing in that neighborhood. |
or psychological injuries, restricted opportunities, human rights violations, and negative environmental impacts. It is important to assess the distribution of outcomes for potential biases or inequities across demographics, especially when ML systems make predictions about or directly impact people. Common types of biases include but are not limited to, sample bias (when the data are not representative of real-world conditions), automation bias (when human operators over-rely on ML outputs), label bias (when choice of categorical label groups populations in potentially discriminatory ways), and other forms of demographic bias (when ML inadvertently discriminates across demographics even if demographic information is not used a feature, because of covariance with other features). It is essential to consider these kinds of potential risks before deploying an ML model into the system.
#6 - ML Performance Monitoring and Correction
It is important to plan for ML monitoring from the outset. ML models, unlike traditional models transportation agencies are more accustomed to deploying, are inherently non-deterministic. An ML model that works as expected during a pilot could later fail for a variety of reasons (e.g., data drift or model drift). Drift occurs when after training and deployment, the distribution of data shifts from the data the model was trained on, leading to inaccurate model outputs. For instance, traffic patterns changed significantly after the COVID-19 pandemic, meaning ML systems trained on pre-pandemic data would be poorly equipped to handle this new scenario. Therefore, it is helpful to plan regular tests to assess whether drift or failures are imminent. If so, it is also important to have rollback plans in place (e.g., switch back to staff manually performing the task) to ensure the overall system continues to operate smoothly. For example, in anticipation of model drift over time, the DelDOT case study interviewee mentioned that their team has included capabilities for the ML tools to update themselves by retraining on new data either on a fixed schedule or based on observed performance degradation (see Chapter 3 in Cetin et al. 2024).
| Planning Question #6 | Hypothetical ML Pilot in Transportation Example |
|---|---|
Have you identified the process for system rollback and error identification/correction?
|
The asset management team will want to continue to monitor the ML model. They may also want to manually validate at least a subset of ML classifications to ensure the ML model is performing as expected on the new data. Generally, an ML model trained on last year’s asset inventory data will perform best on data that looks very similar to that data. If this year’s asset inventory image data looks different (e.g., different distribution of regulatory signs, higher image resolution, or changes in lighting conditions or weather) then the ML model may not perform as well. If the ML model performs below the pre-determined threshold for acceptance (i.e., 90% F1-Score, with no more than a 3% false negative rate), then the asset management team may need to temporarily pause the use of the ML model, revert to their previous manual process, and consider model retraining. |
ML Pilot Schedule
The initial ML pilot planning, including its scope, will inform schedule and cost planning. Like scope planning, schedule planning for an ML pilot project may involve more flexibility, iteration, and uncertainty compared to traditional projects. Often, agile or hybrid methodologies are used for ML projects to accommodate the need for regular stakeholder feedback and iterative enhancements. While an ML pilot schedule may not need to be fully fleshed out from the onset, it can be helpful to understand and lay out key steps and expected durations (subject to change) in the ML pilot schedule, such as the following:
- Project kickoff and scope consensus: While most projects begin with this step, it is especially important to bring all stakeholders to the table at the very beginning, and regularly thereafter, for a new ML pilot project. Because of a lack of familiarity with ML, some stakeholders may not have accurate expectations of the ML functionality proposed. Some may be skeptical while others may be overly optimistic. Educating stakeholders on both the possibilities and potential challenges of the ML pilot could help set realistic expectations and foster buy-in (Vasudevan 2022b). For example, the City of Detroit emphasized that understanding ML’s capabilities and constraints and being realistic in what it can and cannot do is important, as learned during their ATCMTD deployment (Vasudevan et al. 2022b). The staff involved do not need to be experts, but having some baseline knowledge is helpful. Bringing stakeholders to the table during the planning process allows them to share their goals and concerns for the ML application. It also allows the agency’s ML team to better understand where their stakeholders stand in terms of the importance of the ML application’s interpretability, explainability, reliability, and performance. Additionally, meeting with the team and stakeholders early on can serve as an opportunity to further discuss and reach a consensus on key scope elements mentioned in the previous section.
- Data collection: Depending on the agreed-upon pilot scope and ML task, additional data collection could be a necessary early step in the project. The team could decide to collect the data directly with existing agency resources, collect the data directly by buying additional sensors, and/or procure additional data sources. The time required for each of these data collection approaches depends on a variety of factors, such as the availability of sensors (are they available for use by the agency already or do they need to be purchased and installed?), the scale of the data collection effort (how much data will be collected?), the nature of the data to be collected (will the data collection involve PII?), and data storage availability (how much new data will need to be stored?).
- Data processing: All data, including existing data sources and any newly collected data sources, will likely need to undergo some pre-processing from their raw format before they are used in the ML pipeline. ML practitioners may need to impose structure and/or label the data to make them usable for decision-making (Steier 2021). Annotating or labeling the samples can take a nontrivial amount of time and effort. For example, researchers from Vanderbilt University supporting the Tennessee DOT’s ATCMTD deployment decided to manually annotate 350,000 3D boxes with 8 points each to track vehicles in video frames when they could not find sufficient, high-quality existing 3D data to use (Vasudevan et al. 2022b). The case study interviewee from the DelDOT mentioned that a lack of labeled data led the team to recruit interns and TMC staff to help gather and provide labels to footage from CCTV cameras that would power their machine vision applications (see Chapter 3 in Cetin et al. 2024). Depending on the approach decided in Decision Gate #2, non-agency staff, such as vendor or consultant staff, could assist with data processing and labeling. For example, the case study interviewee from the Nebraska DOT mentioned that the vendor did any required image labeling for model training and testing for their guardrail and pedestrian crossing detection applications (see Chapter 3 in Cetin et al. 2024). This offers the potential to save some time if existing agency staff have minimal bandwidth for data labeling.
- Iterative model development via the ML pipeline: Please see Step 5: Execute Pilot for details on the ML pipeline, which includes but is not limited to data preparation, feature engineering, model training and testing, and model validation. Steps in the ML pipeline are executed iteratively during the ML model development process until the trained model reaches an acceptable performance threshold. The amount of time required to reach that performance threshold depends on a variety of factors, such as data scientist/developer availability, use of pre-trained models (e.g., YOLO-neural architecture search for object detection or LLMs for other tasks), and task complexity. For an ML pilot, assuming the data have already been
- collected and processed, the ML model development could take as little as a week or as long as a few months.
- ML model integration into existing system: When asked in a survey about the period the agency needed to develop and implement their ML application, the majority of respondents (85%) indicated that it took 2 years or less for their agency to fully implement/develop their application (see Chapter 2 in Cetin et al. 2024). However, full integration of an ML model into the existing system could take longer. For example, the Missouri DOT mentioned that it took longer to deploy their ML technology than expected due in large part to the many vendors involved in different parts of the project (Vasudevan et al. 2022b). Additionally, as is often the case when moving a new technology from development and testing to real-world deployment, unforeseen complications inevitably arise, which can delay the implementation schedule.
ML Pilot Costs
Like other transportation project costs, ML pilot costs are driven by the project scope, schedule, and resources necessary to execute. Unlike other more traditional transportation projects, there may be greater uncertainty surrounding some of the main cost drivers, such as digital infrastructure-related costs and labor costs for development. ML pilot costs are highly dependent on the existing supporting infrastructure, technologies, and trained staff available to support the pilot. While sensor, data, storage, and computing costs have continued to come down over time, their cost structures have increased in complexity. The types of offerings have expanded to support an increasing variety of use cases and scales. For example, the interviewees from the Missouri DOT team shared example estimated costs for their supplemental data purchasing agreement for their predictive analytics module, which was broken down into three cost categories: the data and analytics bundle, integration package, and proactive response and computer-assisted drafting (see Chapter 3 in Cetin et al. 2024).
It can be difficult to find cost information from data and ML vendors online without providing personal/organizational information and requesting a quote. The ITS Deployment Evaluation website, hosted by the U.S. DOT ITS JPO, provides a database of system and sample unit costs from publicly available evaluation reports, journal articles, and other sources. For example, one of the cost entries mentions that machine vision systems offered by Mobileye that enable self-driving taxis are estimated to cost approximately $10,000 to $15,000 per vehicle, according to a source citing data from the equipment manufacturer from 2020 (Lee 2020).
Table 13 shows example ML pilot projects from the Delaware, Missouri, and Nebraska DOTs in order from smaller scale projects to larger scale projects and key lessons learned related to costs (see Chapter 3 in Cetin et al. 2024).
Budgets need to not only support initial development costs but also ongoing maintenance expenses to sustain the system after the initial pilot project is finished (INFORMS Organization Support Resources Subcommittee 2019). This important consideration is discussed in greater detail in Step 8: Operations & Maintenance in this roadmap.
Table 13. Examples of ML pilot best practices and lessons learned related to costs from case studies.
| State DOT | ML Projects | Best Practices and Lessons Learned for Costs |
|---|---|---|
| Delaware DOT | Statewide AI-Integrated Transportation Management System | The team expects variable costs to reduce over time as department expertise increases, the technology continues to mature, and the state network further integrates. |
| Missouri DOT | I-270 project with predictive, video, and weather analytics components | Technology costs were generally in line with initial expectations. Labor costs for consultants were more difficult to estimate properly since they would rise proportional to the increased amount of reporting required for adding data, adding functionality, and supporting system integration. |
| Nebraska DOT |
Two pilot projects:
|
Both projects were cost-effective for Nebraska DOT as they were able to capitalize on existing image data and had well-defined scopes with clear goals that helped simplify project execution. |

Step 5: Execute Pilot
Execution of the planned ML pilot is a critical phase in the process of integrating an ML solution for a given transportation application. This section provides an overview of key steps needed to execute the ML pipeline for a pilot project. Transforming a conceptual ML model into a functional prototype requires following a robust methodological approach that allows assessing whether the model outcomes align with agency goals and requirements. Such a methodology includes several steps spanning from data preparation to model evaluation, which are discussed as follows and summarized in Figure 9. Typical machine learning pipeline.
- Data collection and preprocessing: In this step, relevant data are gathered to support model development and evaluation. Such data might be coming from sensors, existing DOT databases, surveys, or other sources. It is important to ensure the quality of the data by checking for inconsistencies, outliers, and missing values. Data visualization tools (e.g., Seaborn, Tableau) and various statistical approaches (e.g., outlier detection methods) could be employed to aid in checking data completeness and quality. In addition, most ML models require labeled data
- for model training. Labeled data refer to datasets that have been annotated with informative tags or labels. It is critical to ensure that sufficient labeled data are available if pursuing a supervised or semi-supervised learning approach (see the Glossary of Key Terms for definitions of key terms). If not, options for creating or acquiring labeled data need to be identified. This could involve manual labeling efforts by experts, leveraging crowdsourcing platforms for data annotation, or employing techniques like semi-supervised learning that can work with smaller amounts of labeled data. It should be noted that this step could be one of the most time-consuming and labor-intensive parts of the entire ML pipeline, especially when a meticulous process must be followed to clean and label large datasets.
-
Feature engineering: This pertains to selecting relevant attributes (features) from the data or creating new ones that are expected to be helpful in model predictions. The useful features are those that improve the performance of the ML model. Removing irrelevant or redundant features can make the models simpler, less prone to overfitting, and increase model interpretability. There are several methods for feature engineering: feature transformation, selection and creation, and dimensionality reduction. Brief descriptions of these, based on the summary definitions generated by ChatGPT-4, are provided as follows:
- – Feature transformation: Converting categorical data (e.g., weekend versus weekday) to numerical values (e.g., 0 and 1), log transformations (to handle skewed data), and scaling values to a range (e.g., from 0 to 1) are examples of transformations, which can make it simpler for the ML algorithms to understand and model the data.
- – Feature selection: Identifying features that have the strongest relationship with the output variable and iteratively evaluating which subset(s) of features yield the best model performance are two of the methods employed by feature selection. In addition, some algorithms perform feature selection as part of the model training process (e.g., Lasso regression).
- – Feature creation: Creating new features by aggregating existing ones (e.g., sum, average) or by combining features to capture interactions between two or more variables, and binning or splitting data based on some thresholds are some examples of feature creation or construction.
- – Dimensionality reduction: High-dimensional data (data with many input variables) can make ML complex and prone to overfitting. There are several methods for reducing the number of dimensions including PCA, singular value decomposition, and linear discriminant analysis. These methods use different algorithms to project the data onto a lower-dimensional space while preserving important information.
It should be noted that feature engineering might not be needed for all ML methods. For example, DL models typically learn the importance of different features from the data automatically, without the need for user input.
- Data splitting for training, validation, and testing: To ensure that the developed models are generalizable, the available data need to be split into three parts: training, validation, and test sets. Training data are used to find the best model parameters, whereas the validation data are for fine-tuning or preventing overfitting of the model to the training data. The test data are used to assess the model’s performance on unseen data. The quality of the model is primarily assessed based on the outcomes observed on test data. In cases where data are limited, cross-validation may be a preferred splitting and evaluation approach.
- Model selection and training: There are various ML models and algorithms, ranging from regression models to complex NN. Expert knowledge is needed to select an appropriate approach for the task at hand. For example, to solve a classification problem one can consider decision trees, support vector machines, and NN, among others. Once a model is selected, its parameters need to be adjusted so that it can learn the patterns present in the data. This is done through the model training process. In addition, any hyperparameters (e.g., depth of decision trees, number of layers, and learning rate in NN) need to be considered for optimization as well, since varying them can impact the model performance significantly. Various techniques, including grid search, could be utilized to fine-tune these parameters.
-
Model evaluation: Once the model is trained based on the data, its performance is evaluated using the test data. This is accomplished by computing and analyzing common metrics including accuracy, precision, recall, mean squared errors, or any other applicable statistics (see the next section for more details about these metrics). The acceptable criteria or threshold for these metrics depends on the specific application. The performance of the model needs to be checked with diverse data to ensure that the model is robust enough for the intended application. For example, if camera images are the input to the model, the user should test the performance of the model with images collected under different weather and lighting conditions to ascertain its performance under such diverse environments. A model may perform well under one set of conditions but less so under different conditions. Therefore, the agency may even choose to deploy the model only when the conditions are favorable. In addition to the model’s accuracy and its robustness, depending on the type of application, model interpretability may also be critical for the agency.
- – Model interpretability: ML models (especially NN) are often criticized for being “black boxes” because of the lack of transparency in how these models process input data and make predictions. Generally, the more complex a model is, the less interpretable it is. Model interpretability may become more important when there is a need to understand how and why an ML model makes certain predictions or decisions. This may be needed for regulatory compliance, diagnosing the problems when they arise, obtaining public acceptance, and gaining trust in the systems. In such cases, ML models that are inherently more interpretable (e.g., linear regression, decision trees, and logistic regression) might be preferred. For more complex models (e.g., NN), there are various techniques (Molnar 2023) that help explain the contribution of each feature to the model’s prediction. These complex models could also be tested in a controlled environment to understand how the model behaves under different anticipated conditions to understand its sensitivity to different factors.
- Model deployment and integration into the rest of the system: If the ML model is found to be satisfactory based on the evaluation, the model is deployed in a production environment. This may entail integration with existing systems as needed to provide the necessary input data for the ML model. The model’s performance needs to be monitored continuously, as the input data might vary over time and may potentially include new patterns in data that are previously unseen by the model. If the model’s performance degrades over time, it might need to be retrained or fine-tuned. More information on model deployment can be found in Step 7: Scale Deployment.

Step 6: Communicate Results
After an ML pilot has been implemented, the project team will have to socialize the results of their project among stakeholders to secure buy-in from relevant parties and later expand the project. Although this is good practice for most technology deployments, it is especially true for an emerging technology accompanied by significant hype and skepticism, like ML. It is up to the project team to set realistic expectations for what the ML system can and cannot do, what benefits and challenges they have documented, and what a realistic timeline is for achieving full performance. Only by effectively communicating project results and demonstrating value to stakeholders who are not already proponents of the ML implementation will those stakeholders support the expansion of the pilot and implementation of other ML projects down the road.
According to the U.S. DOT’s report on Artificial Intelligence (AI) for Intelligent Transportation Systems (ITS): Challenges and Potential Solutions, Insights, and Lessons Learned (Vasudevan et al. 2022b), lack of trust and acceptance of AI could impede its adoption, successful implementation, or acceptance because of risk aversion, exaggerated expectations, or mistrust. It cites the following factors contributing to the lack of stakeholder buy-in:
- Lack of understanding of AI capabilities because of a lack of familiarity with expected functionality, limitations, and reliability of AI systems.
- Lack of trust in decisions made by AI because of its black-box nature and lack of explainability of some techniques, perceived bias in computer systems, violation of privacy, and removal of the “human element” in systems that affect people’s lives.
- Fear of privacy breaches because of the vast quantities of data required to train AI, including potentially sensitive data.
- Fear of unethical decisions and liability because of concerns about the fairness and acceptability of using computers for decision-making in situations with significant real-world consequences.
Step 3 of this guide (Build Business Case) defines three categories of stakeholders: decision-makers, operators, and the public. Strategies for communicating the value of the ML pilot should consider and tailor their reports to the varying perspectives of these groups. Figure 10 shows some metrics that these audience types will likely find most compelling by using adaptive signal control as an example.
This section begins with a discussion of ML performance metrics, with a specific focus on how to communicate and translate those metrics into system and workflow improvements. It then covers paradigms for human supervision of AI systems, which can help mitigate the lack of trust in decisions made by AI and fear of unethical or “inhuman” outcomes. It then moves on to the importance of assessment documentation and considerations of content that should be contained therein. The section closes by discussing lessons learned from state agencies in their deployments.
Performance Metrics
The Government Accountability Office’s (GAO) report on Artificial Intelligence: An Accountability Framework for Federal Agencies and Other Entities (GAO 2021) distinguishes between
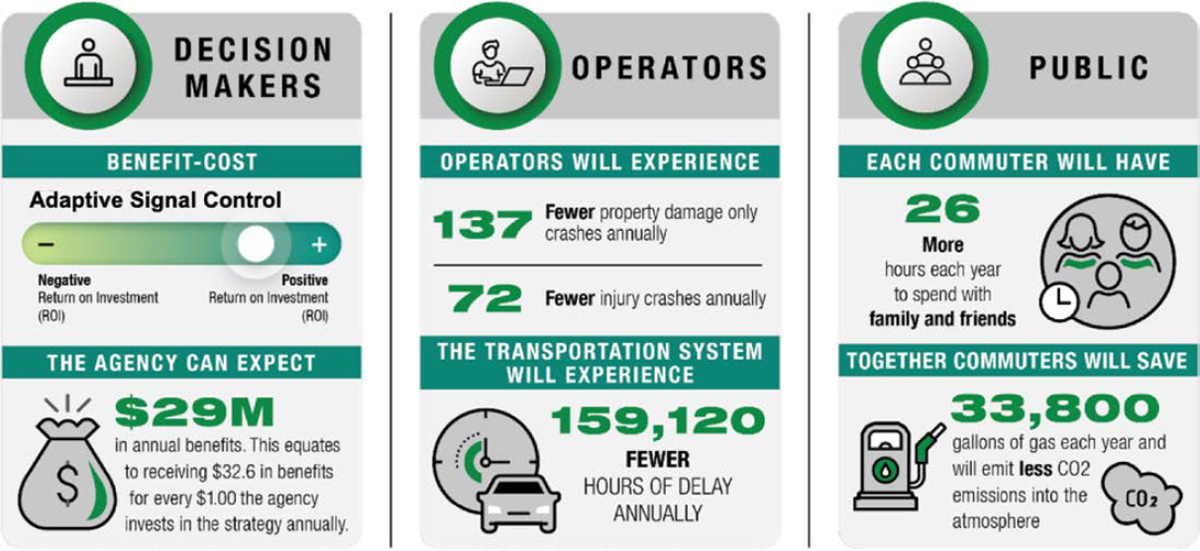
performance assessment at the component level and the system level. Components are technology assets that are building blocks of the AI system, such as the vehicle detection component within an AI-enabled adaptive signal control application. They can include both hardware and software that apply algorithms to data. System-level performance measures illustrate whether the components are working well as an integrated whole and within the operational context. An example might be the overall impact on mobility performance after the implementation of an AI-enabled adaptive signal control application. Project teams should consider both component-level and system-level evaluation and consider the perspectives of different stakeholders when presenting performance assessment results.
ML Performance Assessment
Evaluation of ML algorithms is an expansive field of study and is ever-growing. This text will not cover the full universe of evaluation metrics and processes for choosing which metric a team should use. However, this section summarizes some of the most commonly used metrics for different ML tasks and when it may be appropriate to use them. The team should carefully consider which metrics are the most relevant indicators of their operational success and evaluate their application on that set of metrics. They also will want to collect data on the baseline performance of the system before any implementation of the ML application to compare performance before and after. The team will have to have a reasonable idea of what the agency was doing before the changes spurred by the ML system.
Component-level metrics of an ML algorithm will first depend on whether the task is a regression (continuous label variable) or classification (categorical label variable) task. In the case of regression tasks, some metric based on the residual sum of squares (RSS) is typically used. These include mean squared error and root mean squared error. A non-RSS-based metric that is sometimes used is mean absolute error.
Classification metrics are much more varied, with only a small subset covered in this text. Threshold metrics are dependent on choosing a probability threshold, or cut-off, at which the
algorithm will predict the observation to be positive (e.g., if an algorithm identifies an observation as having a 0.7 probability of being true, and the chosen threshold is 0.8, it will predict the observation to be false because 0.7 < 0.8). Typical classification metrics and when it makes sense to use them are shown in Table 14 (Liu 2022).
The GAO calls for using metrics that are precise, consistent, and reproducible. Testing individual components with quantifiable metrics aligned with program goals helps to provide reasonable assurance that the components are achieving their objectives. Metrics and thresholds should not be chosen arbitrarily but instead should be chosen after a thorough investigation of program goals and how different metrics might or might not relate to those goals (GAO 2021). For instance, precision@K (precision-at-K) is a metric often used when the user has limited resources available for an intervention.
Table 14. Example ML model classification metrics.
| Metric | Description | When to Use |
|---|---|---|
| Accuracy | The number of correct predictions divided by the total number of observations. | This metric is useful when the dataset is balanced (i.e., label classes are evenly distributed across observations), and the value of true predictions is roughly equal to the cost of false predictions. |
| Recall | The ratio of true positives divided by actual (ground truth) positives in the observations. Recall is the percent of actual positives identified by the algorithm. Recall is a threshold metric. | Optimizing for recall is useful when it is imperative to identify a large proportion of positives, and false positives are not very costly. |
| Precision | The ratio of true positives divided by all positives (true and false) predicted by the algorithm. Precision is also a threshold metric. | Optimizing for precision is useful when false positives are costly, and there is a desire to be reasonably sure that the set of predicted positives is in large part true positives. |
| Precision@K | The precision in the set of the top-k items with the highest predicted probability of being positive. | This metric is useful for recommender systems, or when trying to ration limited resources to a set of items for whom those resources would be useful. |
| F1-score | This metric combines precision and recall by taking the weighted average of the two. Therefore, models that score relatively well on both precision and recall will have high F1-scores. | This metric is useful when the goal is to select models that have similar precision and recall scores and also serves as a more robust single-value performance metric in cases of label class imbalance (compared to accuracy). |
| Receiver Operating Characteristic (ROC) Curve | This plot visualizes the performance of a classification model. It is not a threshold metric because it shows model performance over the full range of possible probability thresholds. It is a way to visualize the trade-off between true positive rate (another name for recall) and false positive rate. | This metric is useful when the goal is to get a picture of overall model performance or want to choose a probability threshold. |
| Area Under the Curve (AUC) | The total area under the ROC Curve. Distills the AUC graph using a single number. As it is not a threshold metric, it evaluates models across the whole range of possible probability thresholds. | This metric is useful when the goal is to compare the performance of multiple models across all possible thresholds. |
Choosing a Relevant ML Metric: Bridge Management Hypothetical Example with Resource Constraints
Suppose that a transportation infrastructure asset management team at an agency has a project where they are tasked with identifying bridges for inspection. They know that they have enough resources to inspect 50 bridges in the project horizon. They have decided to use an ML system to recommend which bridges are most in need of inspection.
The team should not use a metric like recall. Since they are limited to only 50 interventions, identifying as many true positives as possible is not relevant. Instead, they decide to use precision@50 as their metric. This optimizes the chances that the set of 50 bridges that the algorithm predicts as having the highest probability of requiring inspection has the fewest false positives or is as “pure” a sample as possible. This way, the agency is as sure as possible that they are spending their limited resources on 50 locations that matter.
System Performance Metrics
As discussed in Step 3 of this guide (Build Business Case), benefits to the transportation system or agency should be downstream of benefits provided by the successful deployment of an ML system. These benefits typically have more salience for transportation decision-makers, operators, and the general public and as such should be recorded as well. These metrics may come in the form of safety, mobility, efficiency/productivity, and environmental benefits. It is crucial to have a baseline against which the team can compare the ML system scenario. This involves either measuring system metrics before implementation of the ML system or otherwise simulating a counterfactual of what the agency would be doing in the absence of changes because of the ML. For instance, in the previous example involving an agency prioritizing bridges to inspect, the system-level performance metric might be the proportion of bridges that actually required inspection to those that were inspected. The team would come up with a baseline proportion of those needing inspection to those that were inspected without using the ML model, either through simulation or analysis of historical data. They then would measure the same proportion under the process using the ML model. If they can demonstrate an increase in this ratio, they will have a good case for the value of their model. Agency decision-makers will be impressed by the increased efficiency of the process and operators will be able to devote their time to more meaningful and less tedious problems.
The GAO recommends that when considering deploying ML systems, project teams think beyond typical ML metrics like accuracy and plan to record metrics related to important issues such as security, explainability, robustness, bias, equity, and other social considerations. This is because ML systems deployed into the real world may have significant unexpected deleterious outcomes. As stated earlier, there exists significant distrust of ML systems in practice. Taking seriously these concerns by measuring proxies for these concerns will help the project team convince stakeholders that their deployment plan is safe and responsible.
On the question of bias, the report on Artificial Intelligence (AI) for Intelligent Transportation Systems (ITS): Challenges and Potential Solutions, Insights, and Lessons Learned (Vasudevan et al. 2022b) recommends collecting sufficient data to measure error statistics across different demographic groups. Some naïve practitioners believe that if models are “blind” to a protected status like race or gender then they cannot result in discriminatory outcomes; however, in practice,
this has been proven false. Therefore, collecting this demographic data can help to measure disparate impacts across groups so that bias can be identified and remediated. There exist many hundreds of tests for bias in AI systems, with none being perfect. Practitioners must be thoughtful and consider what aspects of bias and fairness they are worried about in a particular project, and then choose metrics based on those values. Practitioners can schematize risks of bias by considering the severity of potential biased outcomes, the frequency with which they occur, and how easily they can detect those harmful outcomes. One place practitioners could start is the Fairness Indicators toolset produced and shared by Google, which provides a suite of commonly identified fairness metrics for classification models (TensorFlow 2023).
Additionally, the GAO states that the team may want to consider interviews with AI technical stakeholders, legal and policy officials, social scientists, and civil liberty advocates to identify potential biases and mitigation techniques. They state that robustness can be measured by an experimental plan that tests the system on data that the system has not encountered before or with different distributions than the data on which it was trained. The outputs of the algorithm can then be measured, and practitioners can determine if the system is still behaving in a predictable and appropriate manner. Security can be measured by having a “read team” attempt malicious or deliberate errors to make the system do something other than its intended purpose. The outcomes of this process can be measured, recorded, and reported to provide further trust and transparency (GAO 2021).
Human Supervision of ML Systems
The GAO recommends consideration of the level of human supervision an AI system should have before deployment. This is meant to ensure accountability and will help project teams communicate the role of AI and build confidence among stakeholders that their system is trustworthy. The level of supervision should depend on several factors, most urgently on the purpose and potential consequences of the system. A higher level of supervision might be necessary if the system could result in significant consequences, such as those impacting human safety or civil liberties. Table 15 describes the three approaches to human supervision provided by the GAO (GAO 2021).
Table 15. Broad approaches to human supervision of AI systems.
| Supervision Approach | Description | Transportation Example |
|---|---|---|
| Human-in-the-loop | This involves active human oversight of the AI system. The AI only provides recommendations or input, with a human retaining full control. A human reviews the output of the system and makes the final decision. | An AI-based planning application recommends intersections for the installation of traffic signals. The traffic planners receive these recommendations but ultimately decide where to install them based on their expert judgment. |
| Human-on-the-loop | The human is in a monitoring or supervisory role, with the ability to take control if the model encounters unexpected or undesirable results. | A TIM AI system predicts the locations of traffic incidents and automatically dispatches first responders. An operator monitoring the system can decide to take over and move to manual dispatch procedures at any time. |
| Human-out-of-the-loop | There is no human supervision over the execution of decisions, and the AI has full control without the option of human override. | An AI-based adaptive signal control system is changing traffic signal control strategies in real time. There are no real-time feedback or override options for human operators. |
Assessment Reporting
After pilot implementation, project teams will want to draft and disseminate a report with their findings. This report will help increase their stakeholders’ understanding of the value provided by the ML project. The transparency provided by an assessment report helps to build confidence in ML solutions and increase the perceived transparency of the project. The assessment report should explain the problem, the problem solution, outcomes, and implications. It should have a clear message, plainly state the assumptions and limitations of the model, and recommend a course of action. This is also a good point at which to reiterate that optimal performance was not expected during the small-scale pilot meant to develop and test the application, and that model results are expected to improve with more data and iteration.
The GAO lays out several considerations in its performance framework that should be considered. Some of these elements include the following:
- Documentation: Documentation should be done at both the component and system level. The agency should document the AI system’s development, testing methods, metrics, and outcomes. Decisions such as what and why models, parameters, and features selected should be included. The documents should describe test results, iterations, limitations, and corrective actions that were taken.
- Metrics: The metrics selected and the justification for choosing those metrics should be included in the report. The report should explain how the metrics align with project and organizational goals.
- Assessment: The components and system should be assessed against the pre-defined metrics to ensure that they function as intended. This includes documentation on edge case testing, training and optimization methods, data quality assessments, and internal control documentation. Testing documents should be sufficient to ensure system performance, robustness, and detection of unwanted bias.
- Outputs: The intended outputs of each component of the system should be clearly defined and compared with the actual outputs of components once implemented. Outputs should be suitable for the operational context. Model outputs should be consistent with the values of the agency and should foster public trust and equity.
The assessment report’s audience should be kept in mind while writing (INFORMS, n.d.). Consider the day-to-day workflows of the audience groups, what their overarching goals might be, and what skepticism they might have. The ML project team should have a deep understanding of the operations of the department they seek to deploy the model. Having project leaders and developers spend time working with operators to understand specific roles, functions, and processes is proven to show large returns in the quality of results. It also engenders trust in the project team from the broader agency (INFORMS Organization Support Resources Subcommittee 2019). After operators have some experience with the ML system, it is often useful to interview them to ask how their day-to-day interaction with the model is proceeding and if they notice results changing. Investigating functional areas where the model is being ignored as irrelevant is especially useful because the team can uncover where key, perhaps previously unexpected, assumptions have been invalidated. These insights should be included in the assessment report as limitations of the model and areas that can be improved on in further iterations or deployments (INFORMS, n.d.).
Lessons Learned
The case studies provide significant lessons learned from state DOTs deploying ML systems in the area of communicating results with stakeholders and showing the value of their projects. Some of the most relevant lessons are given in the following callout box.
Communicating Results: Lessons Learned from Case Studies
(Chapter 3 in Cetin et al. 2024)
California: Caltrans provided a very clear before-and-after analysis for their machine vision-based pavement condition assessment application. Instead of just reporting typical statistical metrics (e.g., accuracy, recall), they used metrics that were previously used to evaluate the pavement assessment process with manual methods to enable a direct comparison. Although this approach was time consuming (and relatively subjective), it allowed stakeholders to immediately grasp the benefits. This helped to build confidence in the reliability and effectiveness of the ML project.
Missouri: Operators at Missouri DOT were initially unsatisfied with the early versions of the ML applications because they were demonstrating lower accuracy than the previous process. They also did not initially understand the risk scores that the models were outputting. Over time, the project team was able to help educate staff on the metrics and help them understand how ML models would improve as additional training and tuning of models took place. The project team learned the value of educating personnel on the fundamentals of ML and in setting realistic expectations early on.
Nebraska: Early on, leadership at Nebraska DOT was skeptical of ML. They were convinced to pilot a project after hearing about potential benefits of automated data collection, potential cost savings, and improving performance of ML models over time. Because leadership was skeptical about making big investments in ML without proven results, the project team focused initially on low-cost, low-risk applications with clear foundational benefits, specifically guardrail detection and classification of guardrail attenuators and pedestrian crossing detection. They were able to demonstrate the benefits of the technology in these cost-effective pilots with well-defined scopes.

Step 7: Scale Deployment
If the pilot project demonstrated promising results and decision-makers within the agency agree with its potential for system and/or organizational benefits, it may be time to scale the deployment. The ML pilot could be scaled into a larger deployment by location, time, user base, and/or scope. For example, the ML application could be scaled up geographically from one initial test intersection to 15 intersections along a corridor or from one state district office to statewide. It could be scaled up temporally, from the pilot timeframe of a single summer season to year-round operation. It could be scaled up to new users, from an initial user test base of three operators to all twenty operators within an agency. Finally, it could be scaled in its scope, from operating within a single division, such as maintenance, to multiple divisions within the state DOT, such as highway, traffic management, and safety. Each division might intend to use the ML application on different data and in slightly different ways. However, as the ML application is scaled, this process brings important considerations that may not have existed during the pilot.
Data Availability and Consistency
When scaling up the ML application, it is important to ensure that data availability, quantity, and quality meet the needs of the ML application. Practitioners may need to check that the sensors are producing data according to specifications, that the data size is in the right ballpark, that the various data types are all available, and that the distribution of missing values is as expected. With more sensors involved in the scaled deployment, it is important to have a process in place to monitor for potential issues and have a fallback process in the event of sensor failure, malfunction, obstruction, or occlusion. Other considerations for data consistency when scaling to a larger deployment include the following:
- Different sensor vendors: Some changes to sensor calibration and/or data processing may be necessary when vendors or products are changed. For example, if the ML application ingested LiDAR data from vendor A during the pilot but is expected to ingest LiDAR data from vendors A, B, and C once it is scaled, this would likely require some updates to data processing. This can ensure the ML application is correctly interpreting the updated LiDAR data.
- Different points of view: While data inputs with dynamic views, such as pan-tilt-zoom cameras, can be very useful for operators to adjust their views manually and remotely in real-time, this feature could cause issues for ML applications. Unless the ML application was trained on a variety of viewpoints, depths, and angles, it could struggle to generalize if one or more of its input data sources shifts perspective. One method to mitigate this issue could be to train models on modified versions of existing training images and videos. The data scientist can transform the data by lowering the resolution, flipping or rotating the images, zooming in or out, occluding segments of the image, and so forth. By adding these modified versions of images to the training set, practitioners can train more robust models.
- Different units and resolutions: Consistency in the units (e.g., feet, meters, and yards) and resolution (e.g., 2 megapixels [MP], 3 MP, and 4 MP resolution for CCTV cameras) of data can be important to successfully model scaling. An ML application may be able to ingest and process distance measurements in feet without error, but if it was trained to make decisions based on distance measurements in meters, then it will likely provide unexpected results that lead to poor performance.
Data Distribution and Bias
Scaling the ML application by location, time, and/or scope could lead to some variability in the input data. The new input data could potentially look different than it did during ML development and testing during the pilot. It is important to assess just how different the new, broader input data looks before making the ML application operational. If, for example, the pilot intersection only included adult pedestrians, but the scaled deployment will include one or more intersections near elementary schools with children pedestrians, this points to a difference in the data distribution. This underrepresentation of the elementary student subpopulation could lead to unfair or inequitable outcomes by the ML application when it is scaled (Vasudevan et al. 2022b). In this case, the pilot training data were not fully representative of scaled deployment conditions, which means the ML application could require some retraining or fine-tuning to address the potential bias. Another familiar example of data distribution changes leading to poor ML performance is the COVID-19 pandemic, which caused dramatic reductions in vehicular traffic and changes in traffic patterns. This shift in the data distribution led some AI-enabled adaptive signal control systems to exhibit erratic behavior. It is important to have processes in place for continued validation to detect data and performance abnormalities and have rollback processes in place (DIU 2022b).
Insights from Iowa DOT Case Study on Input Data Shift Impacting ML Model
(Chapter 3 in Cetin et al. 2024)
At some point following the deployment of their ML application, the Iowa DOT switched vendors, and this affected the feeds used to inject the data and triggered the need to go back and rework the ingestion process. Some vendors followed the standards for data distribution, but there were slight differences that were discovered later. This impacted the machine learning process because of the input data feed itself.
Generalization/Transferability
Trained ML may have been overfitting on its training data, which could lead to poor performance in new settings (Vasudevan et al. 2022b). It is important to ensure the ML model has undergone robust testing before it is deployed at scale and regularly thereafter, including under various weather and environmental conditions, stress factors (e.g., one or more sensors malfunctions), and uncommon non-recurring conditions. Vendors may promote their AI solutions as being able to work anywhere, but AI solutions are not necessarily designed to work everywhere (Vasudevan et al. 2022b). Agencies are cautioned to beware of vendors claiming their ML solution is universal. For example, an off-the-shelf ML application that was developed and has only been deployed in the southwest United States could struggle to generalize to northern states with very different weather patterns.
System Integration
Scaling from a small pilot to a large, possibly statewide deployment brings new system integration considerations that may not have been present during the pilot. Having multiple deployment locations across the state could give rise to a need for new interfaces (e.g., dashboard) that bring together disparate ML deployments into one location for visualization and monitoring. Having a variety of vendors for different ML applications or components of the ML application
could also bring system integration challenges. Interoperability across vendors or applications cannot be assumed. Finally, legacy systems could struggle to support the addition and integration of new AI-based functionalities at scale, because of software-hardware incompatibility, limited data storage capacities, and limited computational power (Vasudevan et al. 2022b).
New Costs
Scaling the deployment will likely bring new costs that were not included or were insignificant, such as costs for expanding the communications network, purchasing additional sensors, increasing computing power, continuing the SaaS subscription, and sharing information at scale. ML-based applications might require a continuous power supply, communications networks, and advanced servers to transmit and receive large quantities of data for real-time analytics (Vasudevan et al. 2022b). Leveraging existing ITS infrastructure, such as fiber optic cables, CCTV cameras, and other sensors, can help to minimize deployment scaling costs. While the ML application may have been able to run on a single server during the pilot, a larger computing infrastructure may be required to run it at scale. Cloud computing could be a good option to increase computational speeds without having to invest directly in additional hardware (Vasudevan et al. 2022b). The pilot may have included data and/or an ML application subscription with reduced costs for the first year of the trial period. Following the initial trial period, the monthly or annual subscription costs could increase for the same level of service. Finally, new costs could arise from sharing information from the ML application at scale. During the pilot, the ML outputs may not yet have been broadcast, but now that the ML application has been fully vetted, it could be time to display the results to end users. For example, sharing new forms of real-time traveler information with the public could require creating or purchasing a new app.
The main takeaway for this step is that scaling is not just doing more of the ML pilot. Instead, scaling is likely to bring new considerations and costs that are important to understand before deciding if and how to scale the deployment. The following section on Operations & Maintenance digs more into post-scaling considerations (Step 8).
Insights from Case Studies on Scaling ML Deployments
(Cetin et al. 2024)
Data Availability and Consistency: Researchers supporting the Iowa DOT pointed out that data quality from such a vast number of cameras and sensors is not guaranteed and therefore remains a major concern for achieving good prediction and high performance.
System Integration: Because the Missouri DOT worked with different vendors for applications, those applications were not naturally built to coordinate with each other. Once the ML applications were integrated, integration of the systems into the agency’s Advanced Traffic Management System (ATMS) was also onerous. Overall, the integration process was more difficult and time consuming than expected.
New Costs: The Iowa DOT decided that ML models to compute performance measures for its interstates, alert the DOT of non-recurrent conditions, and detect anomalies would be too costly for statewide deployment. Due to the high cost of upscaling such applications for statewide deployment (e.g., high costs of running ML models in the cloud), the researchers decided to adopt simpler models instead.

Step 8: Operations & Maintenance
Understanding the operational and maintenance needs of ML models in transportation applications is an integral part of the development and deployment framework. Transportation agencies must also take into consideration the associated cost of operations and maintenance required to sustain and improve the performance of the models over time. Other challenges may also be encountered when regular model retraining with new data is desirable to fine-tune the models. This can help improve overall performance over the lifecycle of the project and after the project has ended. While this contributes to the overall benefits of the models, it may also increase the operations and maintenance cost of the ML application because of the additional data preprocessing and continuous model training effort.
One mistake often made is treating ML model development and applications as a one-off project and overlooking the needs for ongoing maintenance, data collection and updates, and fine-tuning the models to adapt to changing environmental circumstances. This section of the guide highlights operations and maintenance needs and challenges for transportation agencies to consider before making strategic investments for deploying ML models at scale. It should be noted that the operational and maintenance needs vary substantially for applications that utilize off-the-shelf versus bespoke AI solutions.
Some key considerations for agencies to address the operations and maintenance needs of ML models in transportation include the following:
- Data needs: Continuous collection and processing of data from sensors, cameras, GPS, and various IoT devices provide the developed ML models with the data they need for continuous training and performance improvement. Such data could support various applications including detecting changes in infrastructure assets, and road and traffic conditions. Data quality and availability issues must be identified and addressed through robust validation and filtering mechanisms. Methods to treat missing data, inconsistencies, and inaccuracies may also be required. Large volumes of data also present some challenges in managing, processing, and storing the data efficiently.
- Model retraining: Over time, the environmental conditions may change, leading to shifts in the underlying distributions of the training data and causing what are known as model and data drifts. Such drifts may occur because of temporal, seasonal, or domain-related changes in the application environment. This calls for repeated retraining processes to adjust and prevent degradation in model performance.
- Performance monitoring: The performance of ML models may deteriorate if conditions substantially change over time. This requires regular tracking of model performance in terms of accuracy and precision metrics to detect anomalies or potential degradation in performance that must be addressed and carefully evaluated.
- Scalability needs: As more data become available and the scope of the application becomes larger, scalability and computing issues may arise, causing additional operations and maintenance challenges. As such, scalability must be considered at the early stages of ML model planning and development. See Step 7: Scale Deployment for a further discussion on scalability considerations.
- Interoperability: Over time, with more deployment of ML applications, there will be an increasing need for better integration of those applications with the existing management and infrastructure systems. Such integration requires some level of standardization in communication and data management.
- Security, privacy, and compliance: Addressing potential security threats and privacy concerns associated with the data and ML models is also a high-priority task in the deployment stages. In many cases, full compliance with regulations must be enforced to protect the data and privacy.
- Type of ML models: The operations and maintenance costs of ML applications also vary based on the process used in the development and deployment stage. While off-the-shelf AI tools offer lower costs for setup and deployment, their monthly subscription/maintenance costs are likely higher over the long term compared to custom, in-house models. Additionally, the monthly/annual maintenance cost is highly likely to increase over time as the system grows to support additional training needs and licensing fees. On the other hand, custom ML models are more time-consuming and expensive to develop, while offering lower operations and maintenance costs in the long-term with in-house expertise.
- Expertise: ML models require broad expertise that includes data scientists, ML engineers, and domain experts. This presents a challenge for transportation agencies to retain and fill expertise gaps within the organization during the lifecycle of the ML application.
- Resource allocation: The operations and maintenance costs of ML applications may vary over time because of expected and unexpected upgrades and repairs. While such costs can be challenging to estimate, transportation agencies should refer to the associated costs for similar applications as a guide for making better estimates for their situation. For example, the survey conducted in this project collected some operating cost information from agencies that deployed ML applications. When asked to provide an estimate of the annual operating cost of the ML application, two-thirds (66.7%) of respondents reported the cost to be less than $50,000. Few reported the annual cost to exceed $300K as shown in Table 16. It is important to highlight that as advancements in modeling techniques continue to evolve, the costs associated with deploying ML applications are expected to decrease, making such technologies more accessible and cost-effective for agencies.
The ML journey requires clear objectives, a full understanding of capabilities, and continuous commitment to meet the operations and maintenance needs of the application throughout its lifecycle. By addressing the operations and maintenance challenges and needs, transportation organizations can improve the system efficiency and maximize the benefits of ML models.
Table 16. Estimated annual operating cost of ML application.
| What is the estimated annual operating cost for this ML application? | % (n) |
|---|---|
| <= $50K | 66.7% (10) |
| More than $50K to $100K | 6.7% (1) |
| More than $100K to $200K | 6.7% (1) |
| More than $200K to $300K | 0.0% (0) |
| More than $300K to $400K | 13.3% (2) |
| More than $400K | 6.7% (1) |

Step 9: Expand ML Capabilities
Executing a successful ML pilot, scaling the application, and successfully integrating it into regular operations are important first steps for creating a broader agency AI program. This expansion calls for a broader plan to map out why, how, what, when, and where to expand agency capabilities, otherwise referred to as an enterprise AI strategy. It also calls for enterprise data systems to centralize data assets, trained staff to support the program in new roles such as data quality control and responsible AI, and coordination internally amongst the agency’s staff as well as externally with other stakeholders and agencies.
Enterprise AI Strategy
ML is a means, not an end. It is another, potentially very powerful tool available to agencies in their ever-expanding toolbox to support the safety, mobility, and efficiency of their regions, states, districts, or cities. To ensure the agency uses ML as an effective tool to support its broader objectives, it can be helpful to develop an AI strategy that includes a vision and goals, a roadmap with tracks and prioritized projects, and clear operating models.
Vision.
The vision should paint a clear picture of what success looks like. It could even include phrases such as “we are successful when . . .” to indicate where the agency is headed with ML and why. In addition to a clear and concise vision statement, it is helpful to outline three to five strategic goals as part of the agency’s AI strategy.
Maturity Assessment.
The roadmap outlines the how and what of the agency’s AI strategy. The agency can develop an AI program roadmap by systematically analyzing its current AI maturity level and identifying future initiatives (Steier 2021). There are a variety of capability maturity models available that transportation agencies could use to help assess their AI/ML readiness, such as the following:
- The INFORMS Analytics Maturity Model (INFORMS 2023) includes questions to help organizations assess their organizational, data and infrastructure, and analytics capability readiness.
- The NCHRP Data Management Capability Maturity Self-Assessment (Pecheux et al. 2020) includes 15 data management self-assessment scorecards on topics such as data collection, storage and operations, security, governance, analytics, and dissemination.
- The NCHRP Data Value and Management Assessment Tool (SpyPond Partners and Iteris 2015) walks through a self-assessment process for agencies to assess the value of their data for decision-making and their data management practices, including checklists and other tools.
- The FHWA Transportation Management Toolbox (FHWA 2023), developed over years of collaboration with over 40 stakeholders from FHWA, state DOTs, MPOs, and transit agencies (Spy Pond Partners, LLC, MLP LLC, and High Street Consulting Group 2019), includes a web-based self-assessment tool to help agencies determine their level of performance management maturity.
- The TSMO Capability Maturity Model (FHWA Office of Operations 2016) and the American Association of State Highway and Transportation Officials’ (AASHTO) Transportation Systems Management and Operations Guidance (AASHTO n.d.), developed through collaboration
- with FHWA, AASHTO, SHRP 2, and others, offers detailed guidance documents on strategies to increase the maturity level of agency business processes, systems and technology, performance measurement, culture, organization/workforce, and collaboration based on the self-assessment results.
- The General Services Administration (GSA) AI Capability Maturity Model (GSA - IT Modernization Centers of Excellence n.d.), developed by the AI Center of Excellence within GSA, provides a common framework for United States federal agencies to evaluate organizational and operational maturity levels for AI against stated objectives.
Example Enterprise AI Strategy from the U.S. Department of State
(U.S. Department of State 2023)
The U.S. Department of State released their Enterprise AI Strategy in October 2023, which includes a vision statement, 4 goals, and 3 objectives per goal. The four goals include the following:
- Goal #1: Leverage secure AI infrastructure
- Goal #2: Foster a culture that embraces AI technology
- Goal #3: Ensure AI is applied responsibly
- Goal #4: Innovate
Initiative Prioritization.
Once the agency has described its desired state (i.e., vision, mission, goals/objectives) and assessed its current state in terms of maturity or readiness for ML (i.e., capability maturity), it can list and prioritize ML initiatives to include in the roadmap. Proposed initiatives or projects can be prioritized by key stakeholders based on agreed-upon criteria, such as the estimated reward and risk. Reward considerations could include the agency’s operational value, broader transportation network improvements, the scale of expected impacts, collaboration potential, learning potential, and alignment with other agency initiatives. Risk considerations could include project feasibility, cost, technical challenges, application maturity, data availability, and computational requirements. Lessons learned from previous projects should be incorporated into this process as a feedback loop to help inform future efforts and priorities. Proposed projects considered feasible with high reward and low risk should be the top priority for a potential “deployment track” in the AI roadmap (Vasudevan, Townsend, and Schweikert 2020). Projects with medium reward and low risk could be included in a potential “prototype track.” Projects with high rewards but high risk could be considered for a potential “research and development track” in the AI roadmap. Projects with relatively low reward and low risk may or may not be worth including in the roadmap depending on the agency’s preference.
Ohio DOT Performed a Data Governance Maturity Assessment
(Spy Pond Partners, LLC and Atkins North America Inc. 2021)
Ohio DOT contracted a study to measure the department’s maturity in data governance. A survey was created and administered to key Ohio DOT data business owners. Recommendations from this study were to create a data governance framework and supporting policy and standards.
Operating Models.
Operating models describe how resources will be directed to realize strategic goals (Steier 2021). One of the most critical resources for an ML project is the data scientist staff supporting it, especially in the case of a custom ML solution. Some organizations have centralized data science teams that other teams come to with requests. Others may have data scientists spread out across the organization, each fully embedded within their particular team but potentially isolated from other data scientists. Data scientists could be agency staff with transportation domain knowledge. They could be contractor staff closely embedded within the agency with transportation domain knowledge. They could be contractor staff with minimal transportation domain knowledge relying on agency staff to provide contextual expertise. It is important for the agency to understand which operating models are available to them and consider the pros and cons of the various options if there is flexibility to choose.
Insights from Delaware DOT Case Study on AI Strategic Planning
(Cetin et al. 2024)
Often, when a state or local agency receives grant funding for a project in emerging technologies, those deployments find themselves without ongoing support from the agency after the grant period has ended. DelDOT is aware of such potential outcomes and mitigates that concern by building their programs, including AI-ITMS, into the everyday business functions of the organization. The agency produces an integrated transportation management strategic plan every five years laying out the priorities and focuses of the organization. This promotes collaboration, cross-review, and sustainability across divisions and programs. Capital improvement projects are reviewed by the TMC [Traffic Management Center] Operations team and they include their own earmarks for sensors and hardware needs. Technology is treated as just as important as roadway infrastructure. This integrated organizational approach means that although they have launched the program through ATCMTD grant funding, the outcomes of the deployments will not be left isolated from the rest of the agency’s business functions.
Enterprise Data Strategy
ML applications, like any analytics projects that an agency may want to embark on, are enabled and limited by the data available to teams within the organization. This is not as simple as it sounds. Making data available requires planning and executing an enterprise data strategy – an overarching vision to enable the agency’s data collection, storage, and sharing capabilities. Tasks such as data governance, cybersecurity, data hosting locations and services, schemas, and more fall under the umbrella of an enterprise data strategy.
Because a comprehensive and shared vision requires buy-in from departments across the enterprise, organizations are increasingly appointing executive-level chief data officers to formulate and execute their enterprise data strategies. Without a champion with decision-making authority across departments, it is unlikely that a holistic data strategy can be implemented. Data will remain siloed across different departments, unlinked, and without centralized capabilities for sharing, which could lead to duplicated data efforts and missed opportunities.
This section is split into two sub-sections: business considerations and policy considerations for data systems. The first lays out factors for enterprise data strategies that apply across any enterprise type, whether public, private, or nonprofit. The second goes into considerations that public
agencies, from federal to local, may want to consider because of unique legal considerations and obligations to public service.
Data Systems Business Considerations
According to SAS, a good enterprise data strategy has four key elements (SAS Insights staff n.d.):
- Practicality: It is easy for the organization to continue conducting their daily activities while following the strategy.
- Relevancy: The strategy is contextual to the organization, not some generic plan.
- Evolutionary: The strategy is expected and able to change regularly.
- Connected/Integrated: The strategy synergizes with other systems that flow from or to it.
There are many organizational benefits to developing an enterprise data strategy. Some of these are obvious, such as having an inventory of data sources in the organization, standardizing and rationalizing data architecture, and improving the effectiveness of data quality procedures. Other benefits might be less obvious but could be incurred simply because the organization is demonstrating more intentionality with regard to its data. For instance, the agency may have not closely considered the value, costs, and risks of data that they were collecting before embarking on the enterprise data strategy journey. SAS identifies the following eight reasons that organizations planning to work with big data should have an enterprise data strategy (SAS Insights staff n.d.):
- Helps set priorities with existing data sources. Agencies looking to implement a data strategy must first collect an inventory of all data sources, applications, and data owners. Surprisingly few organizations have a thorough and current inventory of data assets. This allows decision-makers to understand the complexity and scope of their data systems and identify gaps.
- Rationalizes logical and physical data architecture. The data assets inventory can facilitate business and technical conversations about the relevance and relationships between data domains, as well as conflicts and redundancies in terms. The resulting architecture should build a vocabulary that all sides of the agency understand.
- Provides a roadmap to phase out legacy systems. The inventory describes applications and platforms that collect and maintain data, including capabilities systems, the effort involved in sustaining operations, and opportunities for modernization.
- Improves the effectiveness of data quality processes. The strategy will denote the points for data quality monitoring and processes for correction. This can reduce inconsistencies, redundancies, or gaps in data quality activities.
- Requires you to rethink the data you collect, the value, and the risks. Sharing, reporting, storing, and archiving data may introduce vulnerability to regulatory initiatives. This step helps the agency think through the risks of new data collection before ramping up the collection process.
- Avoids the burden (and hardware/storage costs) of unnecessary data. The inventory helps build awareness of the total amount of data collected and stored. This awareness comes from documenting key data life cycles, understanding how much data exist in different systems, and determining how long storing data is required. This helps inform plans for data retirement and alleviation of associated costs.
- Establishes decision-making authority for data governance and data management. The inventory of data assets includes an assessment of accountability and ownership for each data source and application. Establishing mechanisms for accountability through data governance activities is crucial to improving systems over time.
- Anticipates the true benefits of big data to enrich existing data. Having an enterprise data strategy in place allows the organization to plan where to introduce new data for the
- highest value. Processes and human capital will be in place to deal with the difficult task of the introduction of new data sources.
Data Systems Policy Considerations
In addition to typical enterprise data strategy considerations, public agencies have additional responsibilities to act ethically with regard to data and fulfill civic duties to the public. In this area, the Federal Data Strategy Framework proves a fantastic resource (U.S. Office of Management and Budget 2020). The framework lays out the mission, principles, practices, and actions of the federal government to use its data for the public good. Although the federal government may have particular responsibilities, the majority of these points apply to agencies at all levels of government. The key principles fall under the areas of ethical governance, conscious design, and learning culture. All 40 recommended practices are not listed here, but some key highlights include the following:
- Use data to increase accountability.
- Connect data functions across agencies.
- Govern data to protect confidentiality and privacy.
- Maintain data documentation.
- Leverage data standards.
- Design data for use and re-use.
- Communicate planned and potential uses of data.
- Explicitly communicate allowable uses of data.
- Harness safe data linkage.
Workforce
A trained workforce is critical to successfully implementing an enterprise AI/ML strategy and enterprise data systems. Today’s data boom and rapid advances in computing, data science,
Example of Utah DOT’s (UDOT) Statewide Vehicle-Based Data Collection
(Spy Pond Partners, LLC and Atkins North America Inc. 2021)
Asset owners across UDOT were collecting data, but there was no single point of access for these data. This was creating challenges and preventing UDOT from quantifying their enterprise-wide ability to make data driven decisions. To address this, UDOT decided to collect a statewide LiDAR survey of its entire roadway system every two years. The steps they took included the following:
- Inventory Assessment – UDOT worked with a service provider to overcome challenges and collect mobile LiDAR data of their whole roadway system.
- Develop a Data Dictionary – By preparing an asset coding Data Dictionary, UDOT drove consistent, high quality data extraction. They worked across the agency to agree on a set of parameters for each asset type.
- Establish Asset Tiers – UDOT classified and prioritized different tiers of assets for targeting data-informed decision-making.
- Maintain Asset Database – Post LiDAR survey, UDOT worked to complement enterprise-wide data by using mobile applications linked to a newly procured asset management system. This replaced pen and paper tracking, facilitating a more up-to-date asset database.
and various disruptive technologies have created new demands for data engineers and scientists in every industry. AI has become an integral and transformative part of today’s workforce evolution, particularly in the transportation industry because of the significant increase in data-driven roles. Transportation agencies continue to face the challenge of understanding and implementing AI tools and technologies. As a result, the pace of deployment and adoption of AI in transportation applications has been impeded by the lack of skill set, talent, knowledge, and training as highlighted briefly in Step 2 of the guide (Assess Gaps). The critical AI technical skills and data literacy gap in the transportation workforce across the public and private sectors must be addressed to support the deployment and integration needs of AI and ML in the operation and management of the transportation industry at large. Effective workforce development strategies for closing the skills gap by making investments in talent acquisition and development are crucial for staying competitive in today’s rapidly evolving transportation job market. This section proposes strategic initiatives for meeting the short- and long-term AI workforce needs of transportation agencies.
Transportation Curriculum Development
Degree programs such as civil engineering are offered by almost all universities in the United States, but graduates join the transportation workforce often lacking the technical competencies in data analytics and data science. Like the introduction of statistics to engineering curricula decades ago, engineering programs at academic institutions must integrate ML and AI topics into the curriculum for engineering disciplines and interdisciplinary programs to make data science and ML core technical competencies and required skills to improve the readiness of graduates for an AI-enabled transportation workforce.
Academic-Industry Partnerships
In conjunction with the curriculum development efforts, partnerships between academic institutions, transportation organizations, and industry can help align the educational programs with the technical competencies and skills needed in the job market. Examples of partnerships include building internship and co-op programs for students and promoting research collaboration and technology transfer activities for projects involving the use of AI and ML.
Continuing Education and Training Programs
In collaboration with industry and government partners, academic institutions can establish graduate certificate programs or micro-masters for AI and ML in transportation. The continuing education programs will provide an affordable opportunity for current transportation professionals to upskill and reskill while continuing to work full-time in the transportation workforce. Opportunities for AI-focused online training programs through workshops, webinars, and short courses can also be created to help professionals gain specific AI and ML knowledge and skills needed to support their role in the transportation industry. These professional development opportunities are crucial to embracing AI and ML in the transportation sector and accelerating the development and deployment of AI and ML technologies in real-world transportation applications. Professional development opportunities also exist at technical conferences and professional organization meetings such as the TRB’s Annual Meeting. Of mention is the annual Sunday workshop broadly attended and organized by the education and outreach subcommittee of the TRB Committee for Artificial Intelligence and Advanced Computing Applications.
Policies and Investment Decisions
Transportation agencies are also strongly encouraged to explore investment options and incentives for advocating for and embracing cultural change that supports innovation and growth in the AI workforce. Continually engaging in professional development activities and pursuing continuing education opportunities are key to understanding the evolving experience and skill requirements of an AI-powered workforce.
Intra- and Inter-Agency Collaboration
As discussed in Step 2: Assess Gaps, ML solutions require various resources including computational power, a large amount of data, expertise and a skilled workforce in data science, and access to ML tools. State DOTs can pool these resources by cultivating a collaborative environment, which may include multiple departments within the agency as well as other DOTs, public agencies, industry partners, and academia. This will facilitate the sharing of technical ML expertise, software tools, data, and possibly hardware resources. Since ML applications within DOTs are relatively new and the field is rapidly changing, these collaborations allow state DOTs to learn from the successes and failures of others. This in turn can reduce the agency learning curve and help new deployers avoid common pitfalls. Furthermore, collaboration across agencies promotes the development of standardized practices and benchmarks. This would be valuable to all agencies, since common practices and standards in developing ML solutions help create consistent results and facilitate integration with existing systems.
Most modern ML solutions require large amounts of data for model development and testing. State DOTs typically collect large datasets for different programs. Examples include pavement management data, traffic flow data, geospatial data, camera/video feeds, incident data, vehicle telematics data, environmental data, public transit data, and so forth. By harnessing these diverse datasets, state DOTs can develop ML models to support their operations and improve system safety and performance. The key challenge is to integrate and process these different data sources effectively, ensuring data quality and privacy while extracting valuable insights. This can be achieved by effective intra-agency collaboration as these datasets might be curated and maintained by different divisions or offices. For example, data collected for asset management (e.g., the location of guiderails or rumble strips) would also be useful for traffic operations and safety studies. Therefore, intra-agency collaboration is essential to maximize the best use of the data for supporting diverse applications. Intra-agency collaboration helps align different divisions around common goals and strategies. Such collaborations and sharing of data and other resources can lead to more efficient use of funding, personnel, and technology, avoiding duplication of efforts and maximizing the impact of ML projects.
DOTs with sufficient AI/ML programs and resources may even consider creating a separate AI, ML, or data analytics office that offers support to other departments interested in these types of technologies and projects. The office could help to coordinate across different departments, breaking down silos within the agency and helping to overcome issues with lack of knowledge or skills among the workforce.
Building a Community of Practice Around ML – Insights from Texas DOT
(Wyatt 2024)
Texas DOT is building a community of practice around roadway data by growing their Cooperative Automated Transportation (CAT) Program. The program brings stakeholders together to discuss how information and data flow to support a cooperative ecosystem of physical and digital infrastructure. The program has a user group that meets monthly, and whoever is interested in their data is welcome to join to discuss new opportunities for data sharing and usage. This coordination brings the many Texas districts together to discuss the data, find synergies, resolve issues, and more. A similar community of practice model could be helpful for building agency ML awareness and capabilities statewide for state DOTs.
In addition to fostering intra-agency collaborations, state DOTs can also greatly benefit from seeking resources and collaboration opportunities with federal agencies, other state DOTs, academic institutions, and industry partners. For example, the FHWA can provide access to national programs, funding, and policy guidance. Programs like the FHWA’s Every Day Counts (EDC) initiative offer a platform for state DOTs to adopt proven, yet underutilized, innovations quickly. Projects demonstrating innovative applications of ML would be good candidates to be shared and promoted through the EDC program. The EDC program is under the FHWA’s Center for Accelerating Innovation, which serves as the focal point for internal and external coordination to identify and prioritize innovations. Professional organizations, such as AASHTO, offer committees that share resources, standards, and guidelines. The Data Management and Analytics committee, for example, could be a natural space to share developments in ML concerning transportation. Since state DOTs, other transportation agencies, and infrastructure owner-operators tend to operate in a low-risk environment, it is important for them to learn from and build on what other agencies have done in AI/ML. Having an authoritative example can help other agencies garner support for developing and implementing new ML solutions.
Most state DOTs have a long history of partnering with universities and research institutions to create innovative solutions to various transportation needs. Since they are often at the forefront of ML research, collaborating with academia can provide state DOTs access to the latest research, innovative algorithms, computational resources, and a pool of talent in the form of students and researchers. For example, as reported in Chapter 4 of NCHRP Web-Only Document 404 (Cetin et al. 2024), Iowa DOT partnered with Iowa State University to develop ML applications for highway performance monitoring and incident detection applications. These types of partnerships are demonstrated to be helpful to state DOTs in addressing research needs and exploring alternative ML methods and applications that are not yet commercially available.
To gain a competitive advantage in the market, transportation consulting firms, technology companies, start-ups, and product vendors are racing to adopt the latest AI/ML tools into their services and businesses to support their customers, including state DOTs. These industry entities are recognizing the transformative impact AI/ML can have on DOT operations and continuously adding new AI/ML-based products and services. Collaborating with industry can bring in cutting-edge technology and expertise in ML as well as tools, algorithms, and computational resources that can significantly enhance the capabilities of state DOTs in ML applications. State DOTs can leverage these resources for pilot testing of new ML technologies. Of the five case studies conducted for this NCHRP project, four state DOTs partnered with the industry to develop their ML applications.
State DOTs typically do not have sufficient in-house expertise and resources to develop and deploy ML solutions. Therefore, collaborating with other agencies, academia, and industry is essential for the successful development and deployment of ML solutions. These partnerships provide access to a wealth of resources, expertise, and innovative practices, enabling state DOTs to more quickly and effectively adapt ML technologies to enhance the safety, efficiency, sustainability, and equity of transportation systems. For example, DOTs could share their transferable trained models with others hoping to finetune them and apply them to their similar use cases, such as traffic sign recognition or traffic counting. State DOTs can play a leading role in facilitating this kind of collaboration between state agencies, metropolitan planning organizations, other local agencies, industry, and university partners to advance statewide and regional ML applications and workforce development. For example, states can organize technical forums, peer exchanges, or other coordination activities to exchange knowledge and collaboratively advance AI initiatives with value to stakeholders. No state DOT should have to start from scratch when it comes to leveraging and implementing ML in transportation.




































































